 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChrEn: Cherokee-English Machine Translation for Endangered Language Revitalization
Paper and Code
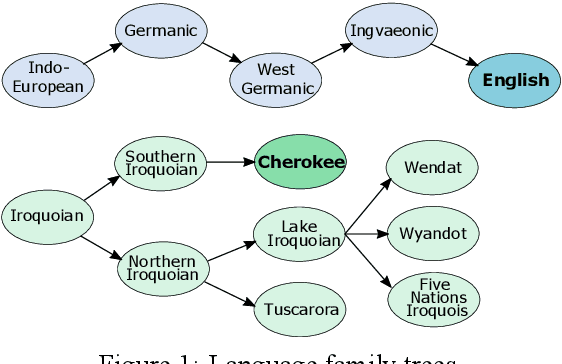
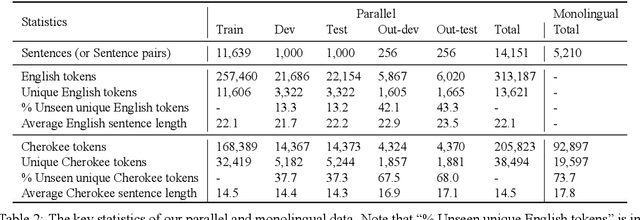
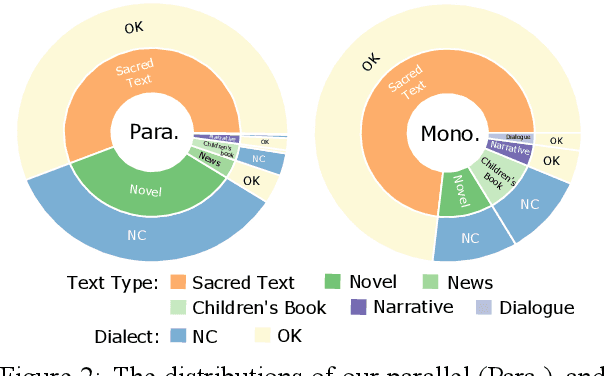
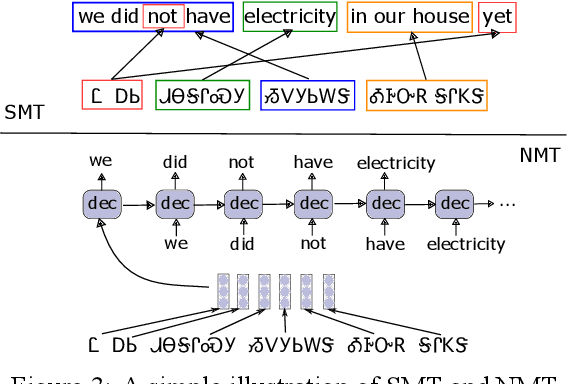
Cherokee is a highly endangered Native American language spoken by the Cherokee people. The Cherokee culture is deeply embedded in its language. However, there are approximately only 2,000 fluent first language Cherokee speakers remaining in the world, and the number is declining every year. To help save this endangered language, we introduce ChrEn, a Cherokee-English parallel dataset, to facilitate machine translation research between Cherokee and English. Compared to some popular machine translation language pairs, ChrEn is extremely low-resource, only containing 14k sentence pairs in total. We split our parallel data in ways that facilitate both in-domain and out-of-domain evaluation. We also collect 5k Cherokee monolingual data to enable semi-supervised learning. Besides these datasets, we propose several Cherokee-English and English-Cherokee machine translation systems. We compare SMT (phrase-based) versus NMT (RNN-based and Transformer-based) systems; supervised versus semi-supervised (via language model, back-translation, and BERT/Multilingual-BERT) methods; as well as transfer learning versus multilingual joint training with 4 other languages. Our best results are 15.8/12.7 BLEU for in-domain and 6.5/5.0 BLEU for out-of-domain Chr-En/EnChr translations, respectively, and we hope that our dataset and systems will encourage future work by the community for Cherokee language revitalization. Our data, code, and demo will be publicly available at https://github.com/ZhangShiyue/ChrEn