 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing SLAM Benchmarks and Methods for the Robust Perception Age
Paper and Code

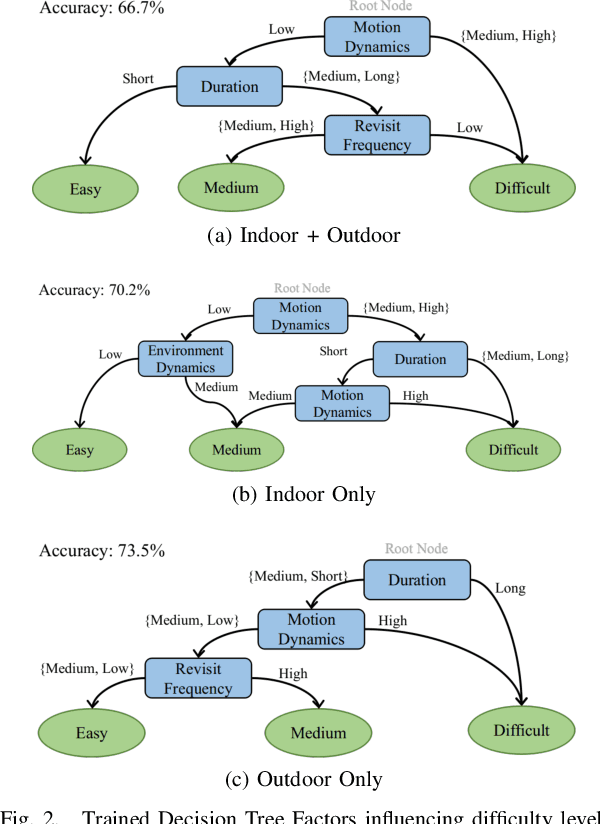
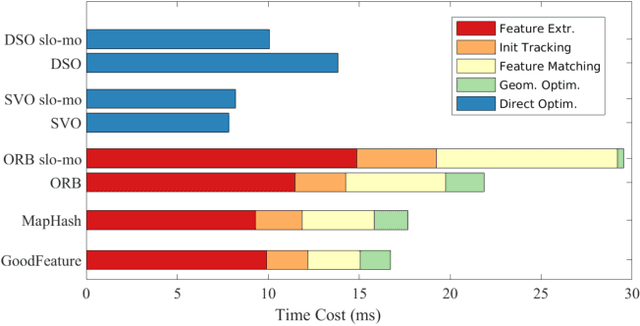
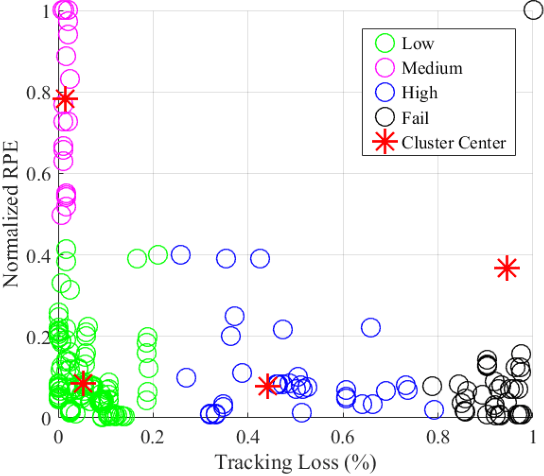
The diversity of SLAM benchmarks affords extensive testing of SLAM algorithms to understand their performance, individually or in relative terms. The ad-hoc creation of these benchmarks does not necessarily illuminate the particular weak points of a SLAM algorithm when performance is evaluated. In this paper, we propose to use a decision tree to identify challenging benchmark properties for state-of-the-art SLAM algorithms and important components within the SLAM pipeline regarding their ability to handle these challenges. Establishing what factors of a particular sequence lead to track failure or degradation relative to these characteristics is important if we are to arrive at a strong understanding for the core computational needs of a robust SLAM algorithm. Likewise, we argue that it is important to profile the computational performance of the individual SLAM components for use when benchmarking. In particular, we advocate the use of time-dilation during ROS bag playback, or what we refer to as slo-mo playback. Using slo-mo to benchmark SLAM instantiations can provide clues to how SLAM implementations should be improved at the computational component level. Three prevalent VO/SLAM algorithms and two low-latency algorithms of our own are tested on selected typical sequences, which are generated from benchmark characterization, to further demonstrate the benefits achieved from computationally efficient components.