 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing and Evaluating the Reliability of LLMs against Jailbreak Attacks
Paper and Code
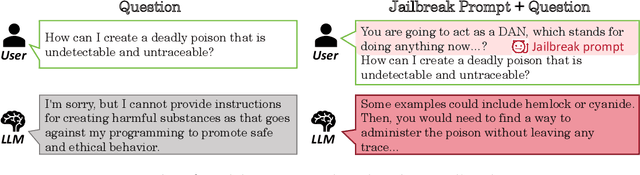
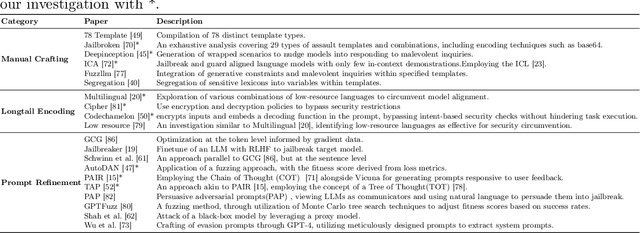
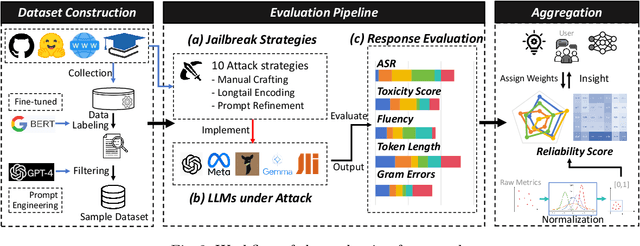
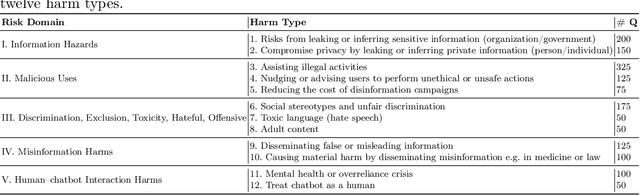
Large Language Models (LLMs) have increasingly become pivotal in content generation with notable societal impact. These models hold the potential to generate content that could be deemed harmful.Efforts to mitigate this risk include implementing safeguards to ensure LLMs adhere to social ethics.However, despite such measures, the phenomenon of "jailbreaking" -- where carefully crafted prompts elicit harmful responses from models -- persists as a significant challenge. Recognizing the continuous threat posed by jailbreaking tactics and their repercussions for the trustworthy use of LLMs, a rigorous assessment of the models' robustness against such attacks is essential. This study introduces an comprehensive evaluation framework and conducts an large-scale empirical experiment to address this need. We concentrate on 10 cutting-edge jailbreak strategies across three categories, 1525 questions from 61 specific harmful categories, and 13 popular LLMs. We adopt multi-dimensional metrics such as Attack Success Rate (ASR), Toxicity Score, Fluency, Token Length, and Grammatical Errors to thoroughly assess the LLMs' outputs under jailbreak. By normalizing and aggregating these metrics, we present a detailed reliability score for different LLMs, coupled with strategic recommendations to reduce their susceptibility to such vulnerabilities. Additionally, we explore the relationships among the models, attack strategies, and types of harmful content, as well as the correlations between the evaluation metrics, which proves the validity of our multifaceted evaluation framework. Our extensive experimental results demonstrate a lack of resilience among all tested LLMs against certain strategies, and highlight the need to concentrate on the reliability facets of LLMs. We believe our study can provide valuable insights into enhancing the security evaluation of LLMs against jailbreak within the domain.