 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChan-Vese Reformulation for Selective Image Segmentation
Paper and Code
Nov 21, 2018
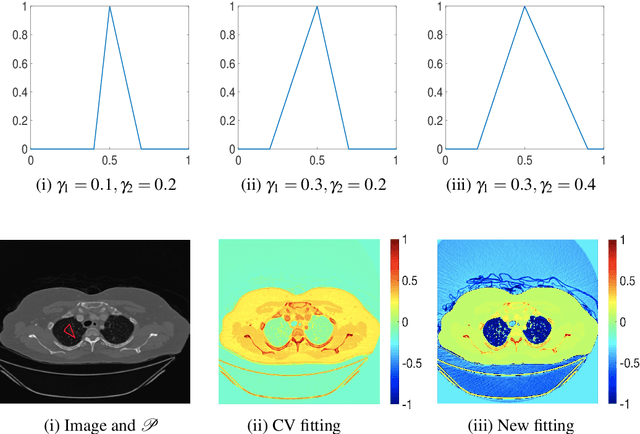
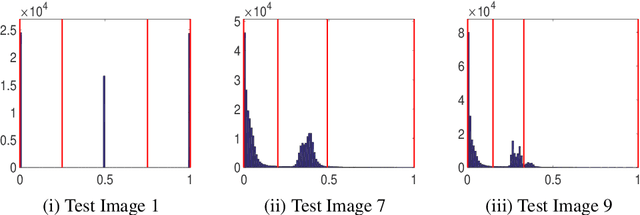
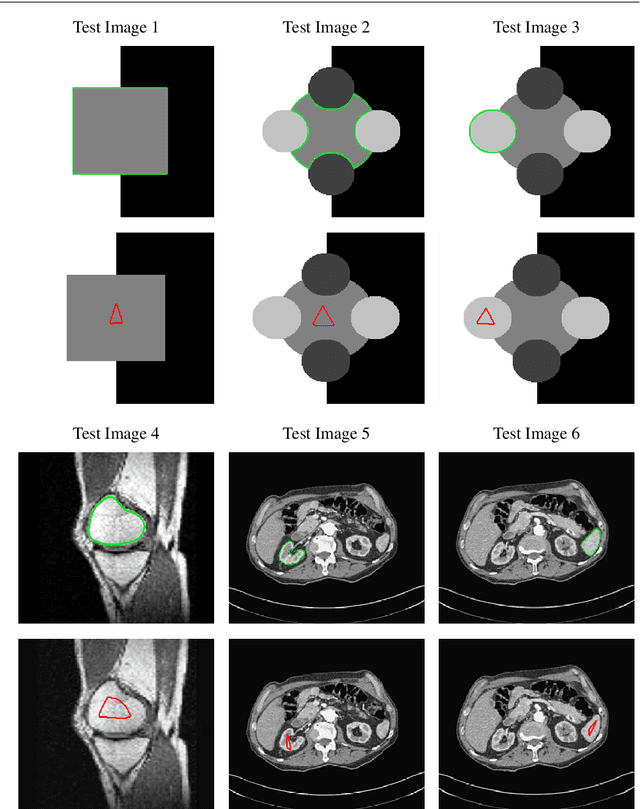
Selective segmentation involves incorporating user input to partition an image into foreground and background, by discriminating between objects of a similar type. Typically, such methods involve introducing additional constraints to generic segmentation approaches. However, we show that this is often inconsistent with respect to common assumptions about the image. The proposed method introduces a new fitting term that is more useful in practice than the Chan-Vese framework. In particular, the idea is to define a term that allows for the background to consist of multiple regions of inhomogeneity. We provide comparitive experimental results to alternative approaches to demonstrate the advantages of the proposed method, broadening the possible application of these methods.