 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChainGAN: A sequential approach to GANs
Paper and Code
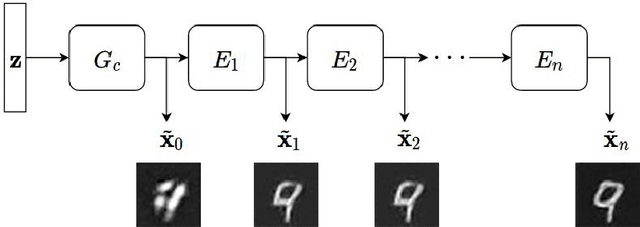


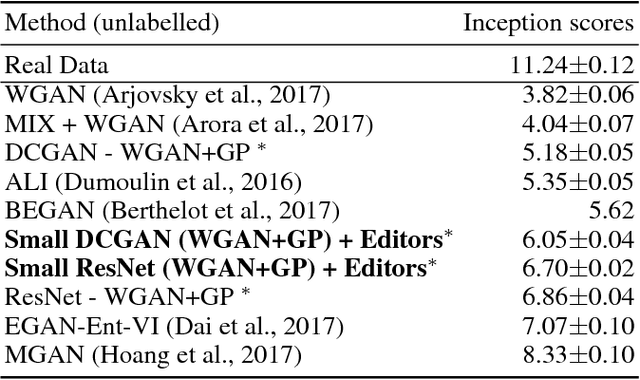
We propose a new architecture and training methodology for generative adversarial networks. Current approaches attempt to learn the transformation from a noise sample to a generated data sample in one shot. Our proposed generator architecture, called $\textit{ChainGAN}$, uses a two-step process. It first attempts to transform a noise vector into a crude sample, similar to a traditional generator. Next, a chain of networks, called $\textit{editors}$, attempt to sequentially enhance this sample. We train each of these units independently, instead of with end-to-end backpropagation on the entire chain. Our model is robust, efficient, and flexible as we can apply it to various network architectures. We provide rationale for our choices and experimentally evaluate our model, achieving competitive results on several datasets.