 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain-of-Thought Prompting for Demographic Inference with Large Multimodal Models
Paper and Code
May 24, 2024

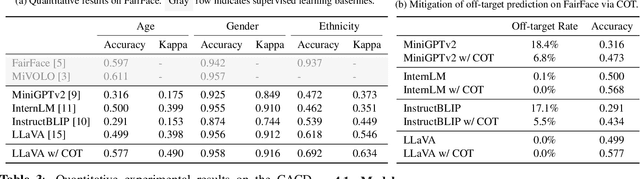

Conventional demographic inference methods have predominantly operated under the supervision of accurately labeled data, yet struggle to adapt to shifting social landscapes and diverse cultural contexts, leading to narrow specialization and limited accuracy in applications. Recently, the emergence of large multimodal models (LMMs) has shown transformative potential across various research tasks, such as visual comprehension and description. In this study, we explore the application of LMMs to demographic inference and introduce a benchmark for both quantitative and qualitative evaluation. Our findings indicate that LMMs possess advantages in zero-shot learning, interpretability, and handling uncurated 'in-the-wild' inputs, albeit with a propensity for off-target predictions. To enhance LMM performance and achieve comparability with supervised learning baselines, we propose a Chain-of-Thought augmented prompting approach, which effectively mitigates the off-target prediction issue.