 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain of Explanation: New Prompting Method to Generate Higher Quality Natural Language Explanation for Implicit Hate Speech
Paper and Code
Sep 11, 2022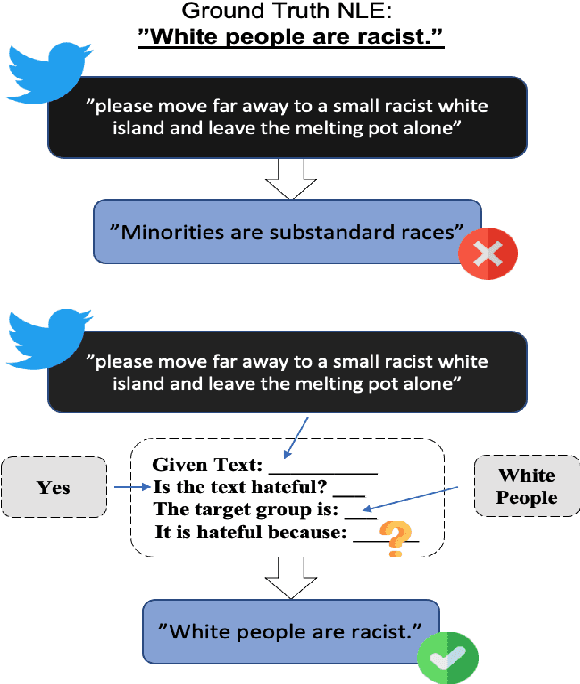

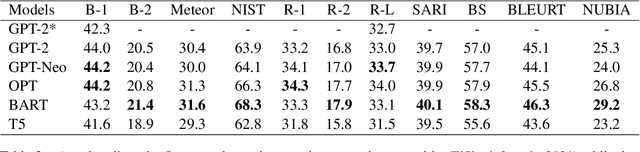

Recent studies have exploited advanced generative language models to generate Natural Language Explanations (NLE) for why a certain text could be hateful. We propose the Chain of Explanation Prompting method, inspired by the chain of thoughts study \cite{wei2022chain}, to generate high-quality NLE for implicit hate speech. We build a benchmark based on the selected mainstream Pre-trained Language Models (PLMs), including GPT-2, GPT-Neo, OPT, T5, and BART, with various evaluation metrics from lexical, semantic, and faithful aspects. To further evaluate the quality of the generated NLE from human perceptions, we hire human annotators to score the informativeness and clarity of the generated NLE. Then, we inspect which automatic evaluation metric could be best correlated with the human-annotated informativeness and clarity metric scores.