 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCenter Feature Fusion: Selective Multi-Sensor Fusion of Center-based Objects
Paper and Code
Sep 26, 2022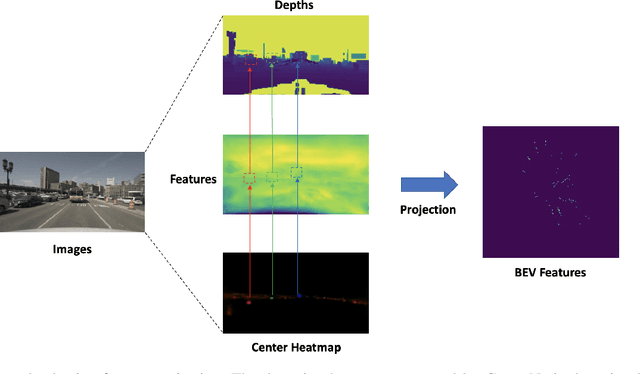
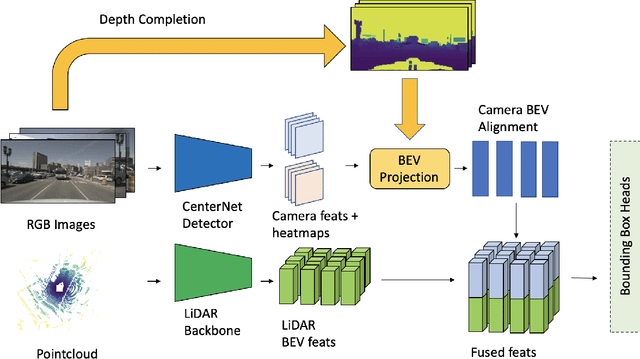

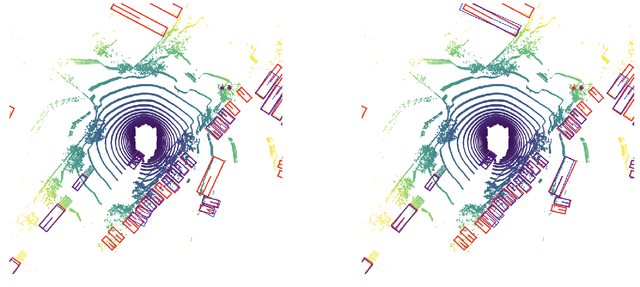
Leveraging multi-modal fusion, especially between camera and LiDAR, has become essential for building accurate and robust 3D object detection systems for autonomous vehicles. Until recently, point decorating approaches, in which point clouds are augmented with camera features, have been the dominant approach in the field. However, these approaches fail to utilize the higher resolution images from cameras. Recent works projecting camera features to the bird's-eye-view (BEV) space for fusion have also been proposed, however they require projecting millions of pixels, most of which only contain background information. In this work, we propose a novel approach Center Feature Fusion (CFF), in which we leverage center-based detection networks in both the camera and LiDAR streams to identify relevant object locations. We then use the center-based detection to identify the locations of pixel features relevant to object locations, a small fraction of the total number in the image. These are then projected and fused in the BEV frame. On the nuScenes dataset, we outperform the LiDAR-only baseline by 4.9% mAP while fusing up to 100x fewer features than other fusion methods.