 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan we do that simpler? Simple, Efficient, High-Quality Evaluation Metrics for NLG
Paper and Code



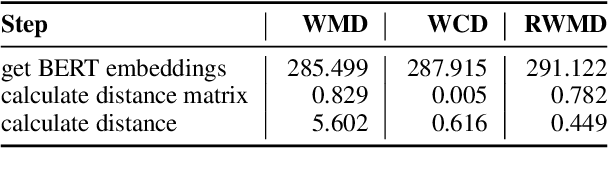
We explore efficient evaluation metrics for Natural Language Generation (NLG). To implement efficient metrics, we replace (i) computation-heavy transformers in metrics such as BERTScore, MoverScore, BARTScore, XMoverScore, etc. with lighter versions (such as distilled ones) and (ii) cubic inference time alignment algorithms such as Word Mover Distance with linear and quadratic approximations. We consider six evaluation metrics (both monolingual and multilingual), assessed on three different machine translation datasets, and 16 light-weight transformers as replacement. We find, among others, that (a) TinyBERT shows best quality-efficiency tradeoff for semantic similarity metrics of the BERTScore family, retaining 97\% quality and being 5x faster at inference time on average, (b) there is a large difference in speed-ups on CPU vs. GPU (much higher speed-ups on CPU), and (c) WMD approximations yield no efficiency gains but lead to a substantial drop in quality on 2 out of 3 datasets we examine.