Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Question Rewriting Help Conversational Question Answering?
Paper and Code
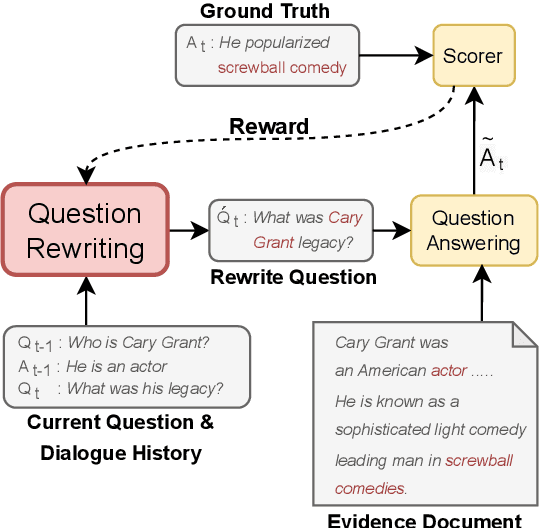



Question rewriting (QR) is a subtask of conversational question answering (CQA) aiming to ease the challenges of understanding dependencies among dialogue history by reformulating questions in a self-contained form. Despite seeming plausible, little evidence is available to justify QR as a mitigation method for CQA. To verify the effectiveness of QR in CQA, we investigate a reinforcement learning approach that integrates QR and CQA tasks and does not require corresponding QR datasets for targeted CQA. We find, however, that the RL method is on par with the end-to-end baseline. We provide an analysis of the failure and describe the difficulty of exploiting QR for CQA.
* Accepted at Workshop on Insights from Negative Results in NLP at
ACL2022
View paper on