 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Domain Adaptation Improve Accuracy and Fairness of Skin Lesion Classification?
Paper and Code
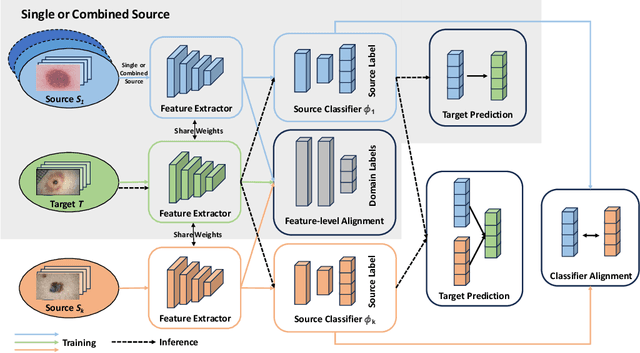
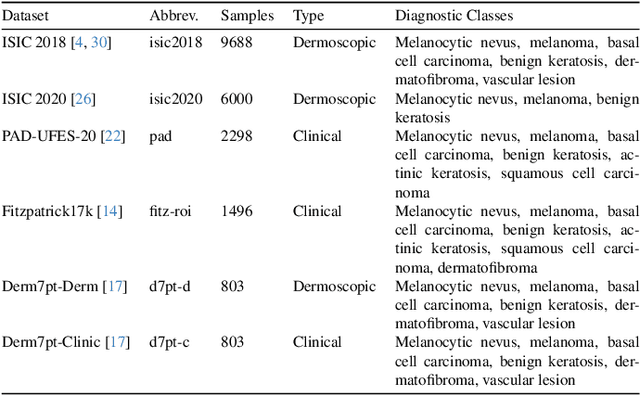
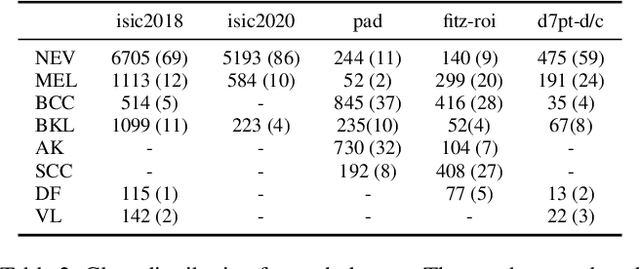
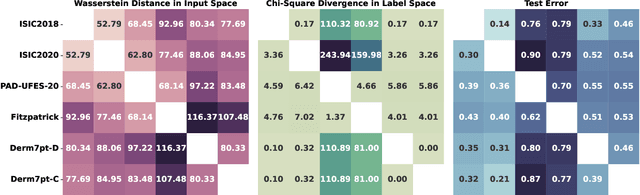
Deep learning-based diagnostic system has demonstrated potential in classifying skin cancer conditions when labeled training example are abundant. However, skin lesion analysis often suffers from a scarcity of labeled data, hindering the development of an accurate and reliable diagnostic system. In this work, we leverage multiple skin lesion datasets and investigate the feasibility of various unsupervised domain adaptation (UDA) methods in binary and multi-class skin lesion classification. In particular, we assess three UDA training schemes: single-, combined-, and multi-source. Our experiment results show that UDA is effective in binary classification, with further improvement being observed when imbalance is mitigated. In multi-class task, its performance is less prominent, and imbalance problem again needs to be addressed to achieve above-baseline accuracy. Through our quantitative analysis, we find that the test error of multi-class tasks is strongly correlated with label shift, and feature-level UDA methods have limitations when handling imbalanced datasets. Finally, our study reveals that UDA can effectively reduce bias against minority groups and promote fairness, even without the explicit use of fairness-focused techniques.