 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrating Data Mismatches in Deep Learning-Based Quantitative Ultrasound Using Setting Transfer Functions
Paper and Code
Oct 04, 2022
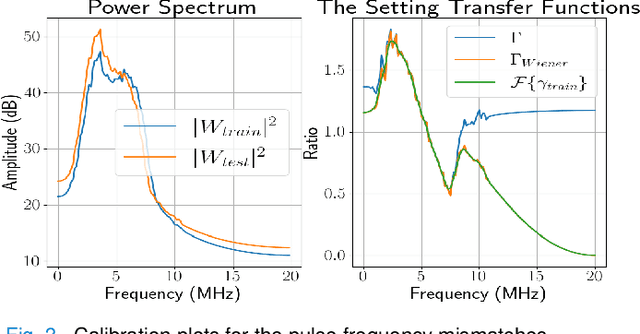
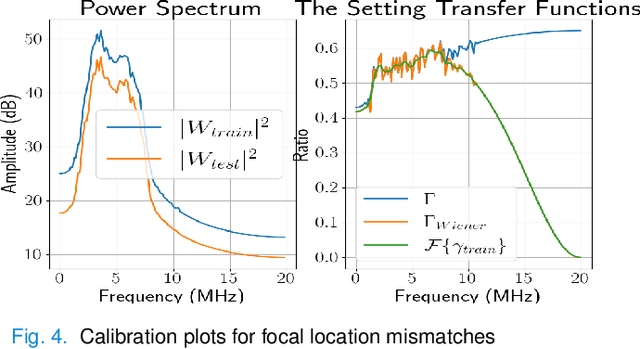
Deep learning (DL) can fail when there are data mismatches between training and testing data. Due to its operator-dependent nature, acquisition-related data mismatches, caused by different scanner settings, can occur in ultrasound imaging. Therefore, mitigating effects of such data mismatches is essential for wider clinical adoption of DL powered ultrasound imaging. To mitigate the effects, ideally we need to collect a large training set at each scanner setting. However, acquiring such training sets is expensive. Another approach could be training on a subset of imaging settings, which makes the data generation less expensive. However, there will still be generalization issues. As an alternative approach that is inexpensive and generalizable, we propose to collect a large training set at a single setting and a small calibration set at each scanner setting. Then, the calibration set will be used to calibrate data mismatches by using a signals and systems perspective. We tested the proposed solution to classify two phantoms. To investigate generalizability of the proposed solution, we calibrated three types of data mismatches: pulse frequency, focus and output power mismatches. To calibrate the setting mismatches, we calculated the setting transfer functions. The CNN trained with no calibration resulted in mean classification accuracies of 55.3%, 64.4% and 70.3% for pulse frequency, focus and output power mismatches, respectively. By using the setting transfer functions, which allowed a matching of the training and testing domains, we obtained mean accuracies of 95.3%, 92.99% and 99.32%, respectively. Therefore, the incorporation of the setting transfer functions between scanner settings can provide an economical means of generalizing a DL model for specific classification tasks where scanner settings are not fixed by the operator.