 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCADMR: Cross-Attention and Disentangled Learning for Multimodal Recommender Systems
Paper and Code
Dec 03, 2024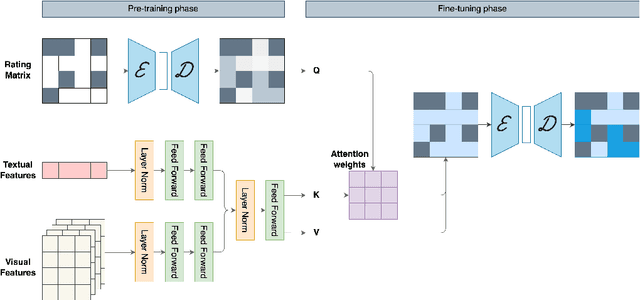
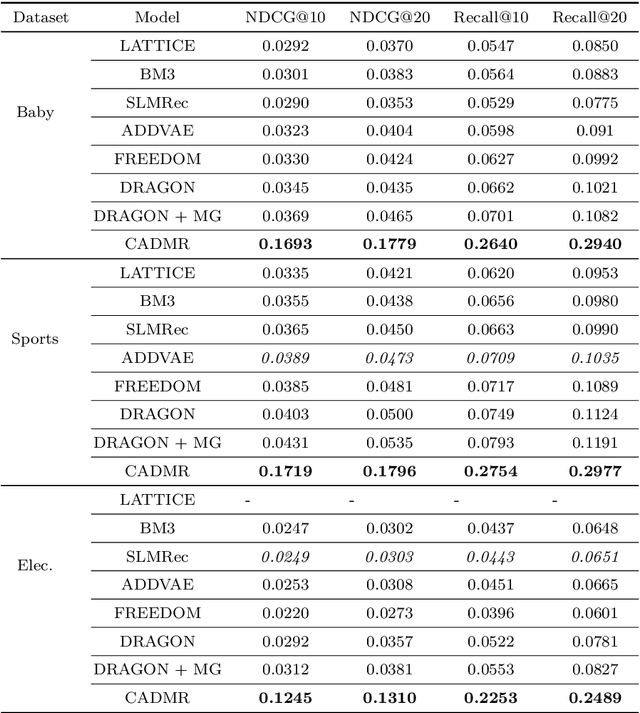
The increasing availability and diversity of multimodal data in recommender systems offer new avenues for enhancing recommendation accuracy and user satisfaction. However, these systems must contend with high-dimensional, sparse user-item rating matrices, where reconstructing the matrix with only small subsets of preferred items for each user poses a significant challenge. To address this, we propose CADMR, a novel autoencoder-based multimodal recommender system framework. CADMR leverages multi-head cross-attention mechanisms and Disentangled Learning to effectively integrate and utilize heterogeneous multimodal data in reconstructing the rating matrix. Our approach first disentangles modality-specific features while preserving their interdependence, thereby learning a joint latent representation. The multi-head cross-attention mechanism is then applied to enhance user-item interaction representations with respect to the learned multimodal item latent representations. We evaluate CADMR on three benchmark datasets, demonstrating significant performance improvements over state-of-the-art methods.