 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC3DVQA: Full-Reference Video Quality Assessment with 3D Convolutional Neural Network
Paper and Code
Oct 30, 2019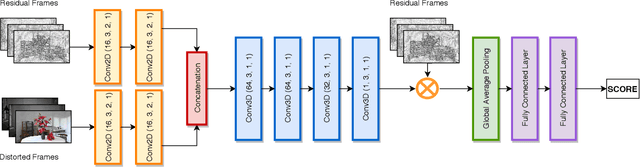
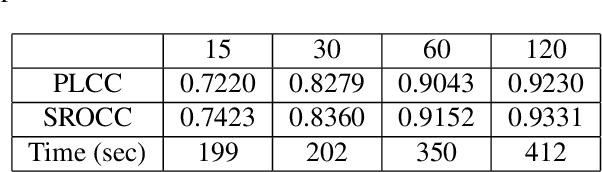

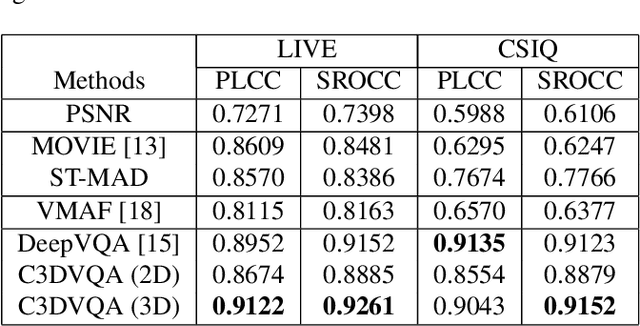
Traditional video quality assessment (VQA) methods evaluate localized picture quality and video score is predicted by temporally aggregating frame scores. However, video quality exhibits different characteristics from static image quality due to the existence of temporal masking effects. In this paper, we present a novel architecture, namely C3DVQA, that uses Convolutional Neural Network with 3D kernels (C3D) for full-reference VQA task. C3DVQA combines feature learning and score pooling into one spatiotemporal feature learning process. We use 2D convolutional layers to extract spatial features and 3D convolutional layers to learn spatiotemporal features. We empirically found that 3D convolutional layers are capable to capture temporal masking effects of videos.We evaluated the proposed method on the LIVE and CSIQ datasets. The experimental results demonstrate that the proposed method achieves the state-of-the-art performance.