 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeByzantine-Resilient SGD in High Dimensions on Heterogeneous Data
Paper and Code
May 16, 2020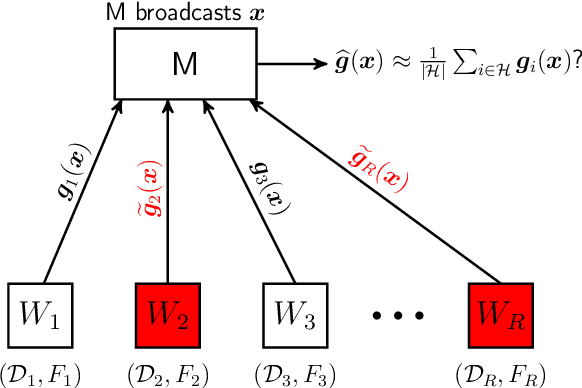
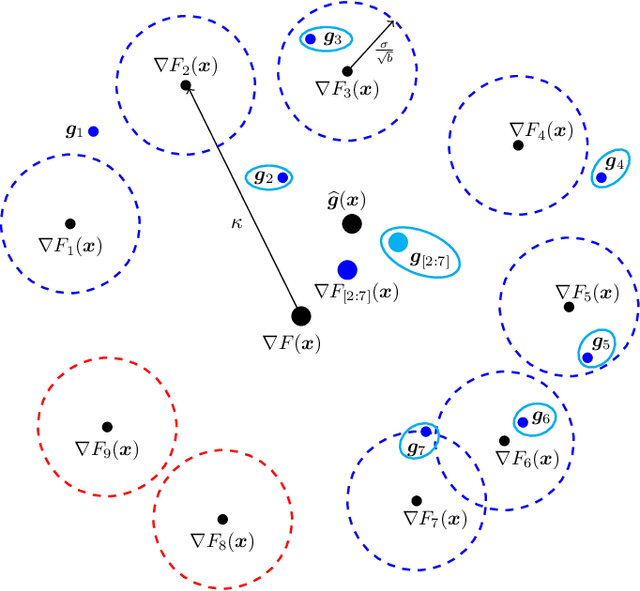
We study distributed stochastic gradient descent (SGD) in the master-worker architecture under Byzantine attacks. We consider the heterogeneous data model, where different workers may have different local datasets, and we do not make any probabilistic assumptions on data generation. At the core of our algorithm, we use the polynomial-time outlier-filtering procedure for robust mean estimation proposed by Steinhardt et al. (ITCS 2018) to filter-out corrupt gradients. In order to be able to apply their filtering procedure in our {\em heterogeneous} data setting where workers compute {\em stochastic} gradients, we derive a new matrix concentration result, which may be of independent interest. We provide convergence analyses for smooth strongly-convex and non-convex objectives. We derive our results under the bounded variance assumption on local stochastic gradients and a {\em deterministic} condition on datasets, namely, gradient dissimilarity; and for both these quantities, we provide concrete bounds in the statistical heterogeneous data model. We give a trade-off between the mini-batch size for stochastic gradients and the approximation error. Our algorithm can tolerate up to $\frac{1}{4}$ fraction Byzantine workers. It can find approximate optimal parameters in the strongly-convex setting exponentially fast and reach to an approximate stationary point in the non-convex setting with a linear speed, thus, matching the convergence rates of vanilla SGD in the Byzantine-free setting. We also propose and analyze a Byzantine-resilient SGD algorithm with gradient compression, where workers send $k$ random coordinates of their gradients. Under mild conditions, we show a $\frac{d}{k}$-factor saving in communication bits as well as decoding complexity over our compression-free algorithm without affecting its convergence rate (order-wise) and the approximation error.