 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuild a Compact Binary Neural Network through Bit-level Sensitivity and Data Pruning
Paper and Code
Feb 03, 2018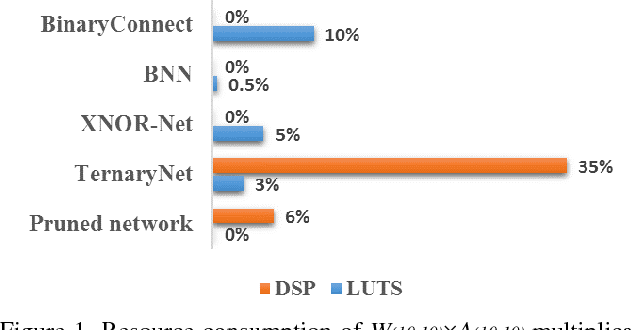
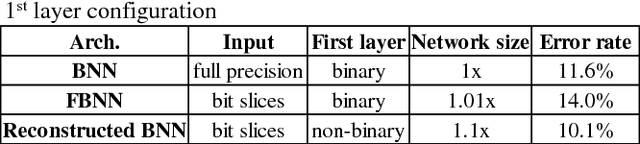


Convolutional neural network (CNN) has been widely used for vision-based tasks. Due to the high computational complexity and memory storage requirement, it is hard to directly deploy a full-precision CNN on embedded devices. The hardware-friendly designs are needed for re-source-limited and energy-constrained embed-ded devices. Emerging solutions are adopted for the neural network compression, e.g., bina-ry/ternary weight network, pruned network and quantized network. Among them, Binarized Neural Network (BNN) is believed to be the most hardware-friendly framework due to its small network size and low computational com-plexity. No existing work has further shrunk the size of BNN. In this work, we explore the redun-dancy in BNN and build a compact BNN (CBNN) based on the bit-level sensitivity analy-sis and bit-level data pruning. The input data is converted to a high dimensional bit-sliced for-mat. In post-training stage, we analyze the im-pact of different bit slices to the accuracy. By pruning the redundant input bit slices and shrinking the network size, we are able to build a more compact BNN. Our result shows that we can further scale down the network size of the BNN up to 3.9x with no more than 1% accuracy drop. The actual runtime can be reduced up to 2x and 9.9x compared with the baseline BNN and its full-precision counterpart, respectively.