Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBRUMS at SemEval-2020 Task 3: Contextualised Embeddings forPredicting the Effect of Context in Word Similarity
Paper and Code
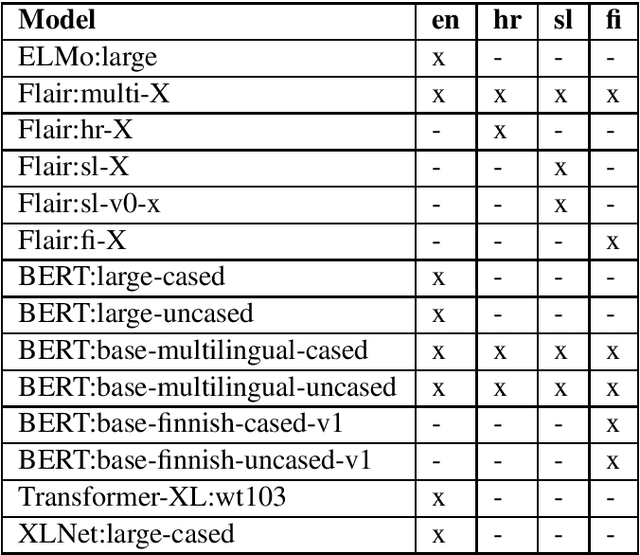


This paper presents the team BRUMS submission to SemEval-2020 Task 3: Graded Word Similarity in Context. The system utilises state-of-the-art contextualised word embeddings, which have some task-specific adaptations, including stacked embeddings and average embeddings. Overall, the approach achieves good evaluation scores across all the languages, while maintaining simplicity. Following the final rankings, our approach is ranked within the top 5 solutions of each language while preserving the 1st position of Finnish subtask 2.
* Accepted to SemEval-2020 (International Workshop on Semantic
Evaluation) at COLING 2020
View paper on