 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Gap: Enhancing the Utility of Synthetic Data via Post-Processing Techniques
Paper and Code
May 17, 2023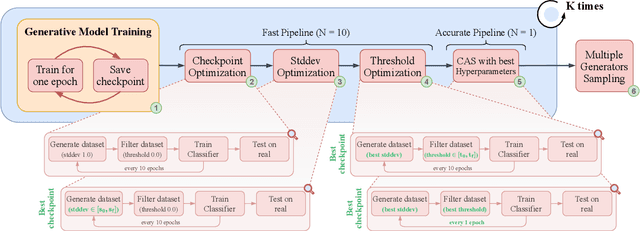



Acquiring and annotating suitable datasets for training deep learning models is challenging. This often results in tedious and time-consuming efforts that can hinder research progress. However, generative models have emerged as a promising solution for generating synthetic datasets that can replace or augment real-world data. Despite this, the effectiveness of synthetic data is limited by their inability to fully capture the complexity and diversity of real-world data. To address this issue, we explore the use of Generative Adversarial Networks to generate synthetic datasets for training classifiers that are subsequently evaluated on real-world images. To improve the quality and diversity of the synthetic dataset, we propose three novel post-processing techniques: Dynamic Sample Filtering, Dynamic Dataset Recycle, and Expansion Trick. In addition, we introduce a pipeline called Gap Filler (GaFi), which applies these techniques in an optimal and coordinated manner to maximise classification accuracy on real-world data. Our experiments show that GaFi effectively reduces the gap with real-accuracy scores to an error of 2.03%, 1.78%, and 3.99% on the Fashion-MNIST, CIFAR-10, and CIFAR-100 datasets, respectively. These results represent a new state of the art in Classification Accuracy Score and highlight the effectiveness of post-processing techniques in improving the quality of synthetic datasets.