Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Adversarial and Nonstationary Multi-armed Bandit
Paper and Code
Jan 05, 2022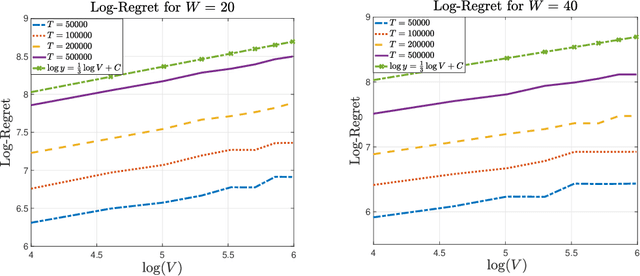
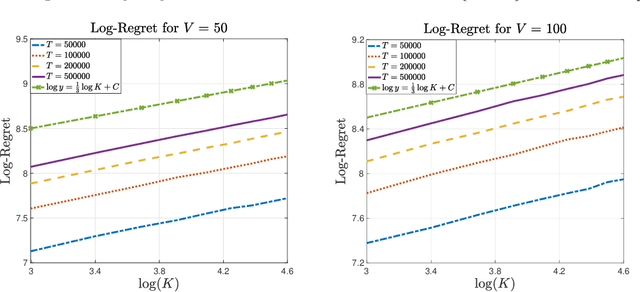
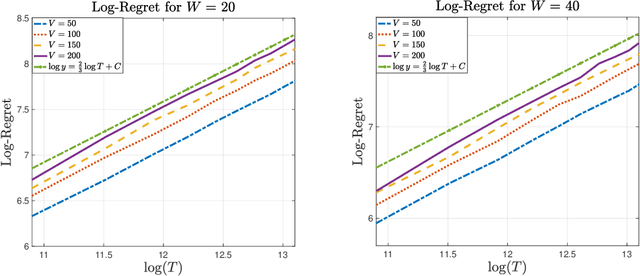
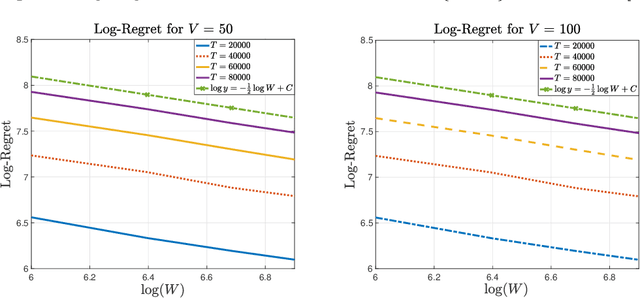
In the multi-armed bandit framework, there are two formulations that are commonly employed to handle time-varying reward distributions: adversarial bandit and nonstationary bandit. Although their oracles, algorithms, and regret analysis differ significantly, we provide a unified formulation in this paper that smoothly bridges the two as special cases. The formulation uses an oracle that takes the best-fixed arm within time windows. Depending on the window size, it turns into the oracle in hindsight in the adversarial bandit and dynamic oracle in the nonstationary bandit. We provide algorithms that attain the optimal regret with the matching lower bound.
View paper on