 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreast tumor classification based on self-supervised contrastive learning from ultrasound videos
Paper and Code
Aug 20, 2024


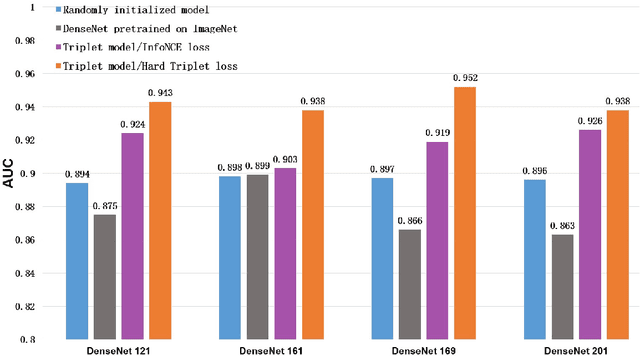
Background: Breast ultrasound is prominently used in diagnosing breast tumors. At present, many automatic systems based on deep learning have been developed to help radiologists in diagnosis. However, training such systems remains challenging because they are usually data-hungry and demand amounts of labeled data, which need professional knowledge and are expensive. Methods: We adopted a triplet network and a self-supervised contrastive learning technique to learn representations from unlabeled breast ultrasound video clips. We further designed a new hard triplet loss to to learn representations that particularly discriminate positive and negative image pairs that are hard to recognize. We also constructed a pretraining dataset from breast ultrasound videos (1,360 videos from 200 patients), which includes an anchor sample dataset with 11,805 images, a positive sample dataset with 188,880 images, and a negative sample dataset dynamically generated from video clips. Further, we constructed a finetuning dataset, including 400 images from 66 patients. We transferred the pretrained network to a downstream benign/malignant classification task and compared the performance with other state-of-the-art models, including three models pretrained on ImageNet and a previous contrastive learning model retrained on our datasets. Results and conclusion: Experiments revealed that our model achieved an area under the receiver operating characteristic curve (AUC) of 0.952, which is significantly higher than the others. Further, we assessed the dependence of our pretrained model on the number of labeled data and revealed that <100 samples were required to achieve an AUC of 0.901. The proposed framework greatly reduces the demand for labeled data and holds potential for use in automatic breast ultrasound image diagnosis.