 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBox Drawings for Learning with Imbalanced Data
Paper and Code

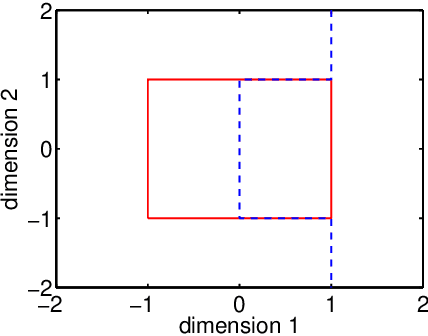

The vast majority of real world classification problems are imbalanced, meaning there are far fewer data from the class of interest (the positive class) than from other classes. We propose two machine learning algorithms to handle highly imbalanced classification problems. The classifiers constructed by both methods are created as unions of parallel axis rectangles around the positive examples, and thus have the benefit of being interpretable. The first algorithm uses mixed integer programming to optimize a weighted balance between positive and negative class accuracies. Regularization is introduced to improve generalization performance. The second method uses an approximation in order to assist with scalability. Specifically, it follows a \textit{characterize then discriminate} approach, where the positive class is characterized first by boxes, and then each box boundary becomes a separate discriminative classifier. This method has the computational advantages that it can be easily parallelized, and considers only the relevant regions of feature space.