 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBounded Coordinate-Descent for Biological Sequence Classification in High Dimensional Predictor Space
Paper and Code
Aug 03, 2010
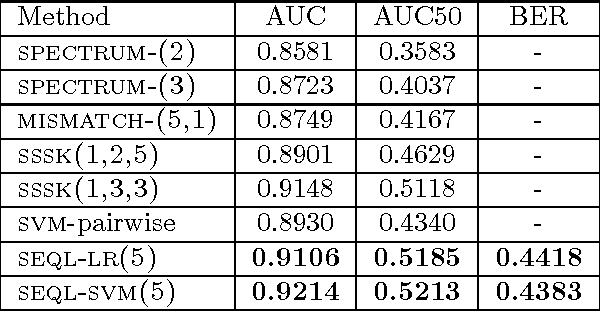


We present a framework for discriminative sequence classification where the learner works directly in the high dimensional predictor space of all subsequences in the training set. This is possible by employing a new coordinate-descent algorithm coupled with bounding the magnitude of the gradient for selecting discriminative subsequences fast. We characterize the loss functions for which our generic learning algorithm can be applied and present concrete implementations for logistic regression (binomial log-likelihood loss) and support vector machines (squared hinge loss). Application of our algorithm to protein remote homology detection and remote fold recognition results in performance comparable to that of state-of-the-art methods (e.g., kernel support vector machines). Unlike state-of-the-art classifiers, the resulting classification models are simply lists of weighted discriminative subsequences and can thus be interpreted and related to the biological problem.