 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBottlenecks CLUB: Unifying Information-Theoretic Trade-offs Among Complexity, Leakage, and Utility
Paper and Code
Jul 11, 2022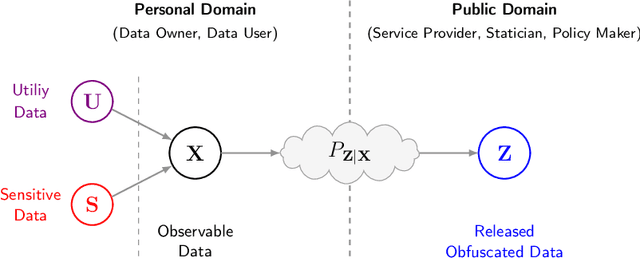
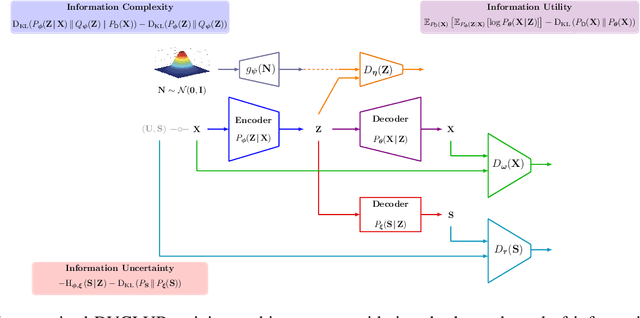
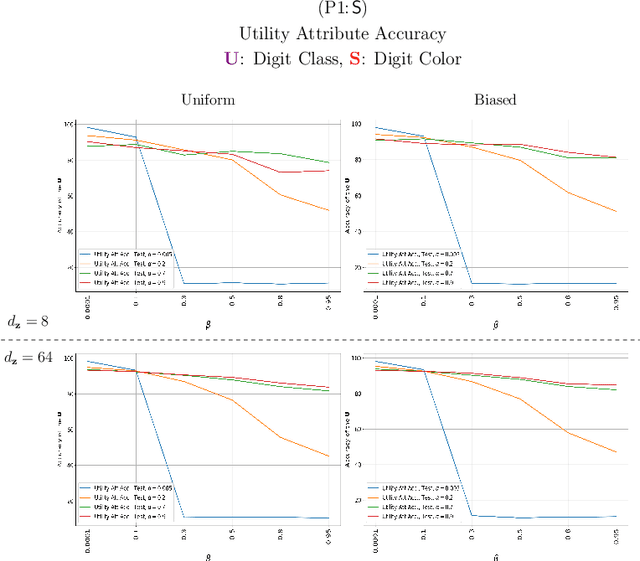
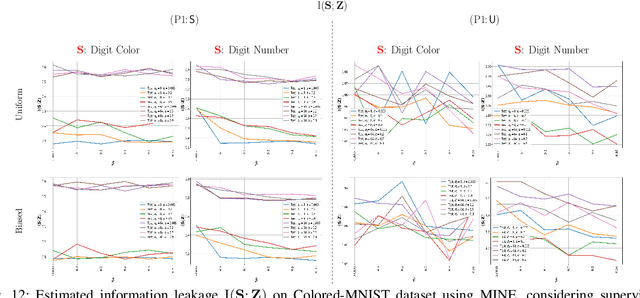
Bottleneck problems are an important class of optimization problems that have recently gained increasing attention in the domain of machine learning and information theory. They are widely used in generative models, fair machine learning algorithms, design of privacy-assuring mechanisms, and appear as information-theoretic performance bounds in various multi-user communication problems. In this work, we propose a general family of optimization problems, termed as complexity-leakage-utility bottleneck (CLUB) model, which (i) provides a unified theoretical framework that generalizes most of the state-of-the-art literature for the information-theoretic privacy models, (ii) establishes a new interpretation of the popular generative and discriminative models, (iii) constructs new insights to the generative compression models, and (iv) can be used in the fair generative models. We first formulate the CLUB model as a complexity-constrained privacy-utility optimization problem. We then connect it with the closely related bottleneck problems, namely information bottleneck (IB), privacy funnel (PF), deterministic IB (DIB), conditional entropy bottleneck (CEB), and conditional PF (CPF). We show that the CLUB model generalizes all these problems as well as most other information-theoretic privacy models. Then, we construct the deep variational CLUB (DVCLUB) models by employing neural networks to parameterize variational approximations of the associated information quantities. Building upon these information quantities, we present unified objectives of the supervised and unsupervised DVCLUB models. Leveraging the DVCLUB model in an unsupervised setup, we then connect it with state-of-the-art generative models, such as variational auto-encoders (VAEs), generative adversarial networks (GANs), as well as the Wasserstein GAN (WGAN), Wasserstein auto-encoder (WAE), and adversarial auto-encoder (AAE) models through the optimal transport (OT) problem. We then show that the DVCLUB model can also be used in fair representation learning problems, where the goal is to mitigate the undesired bias during the training phase of a machine learning model. We conduct extensive quantitative experiments on colored-MNIST and CelebA datasets, with a public implementation available, to evaluate and analyze the CLUB model.