 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootstrapping Vision-language Models for Self-supervised Remote Physiological Measurement
Paper and Code
Jul 11, 2024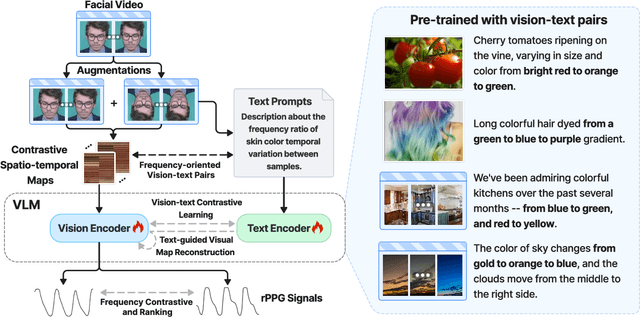



Facial video-based remote physiological measurement is a promising research area for detecting human vital signs (e.g., heart rate, respiration frequency) in a non-contact way. Conventional approaches are mostly supervised learning, requiring extensive collections of facial videos and synchronously recorded photoplethysmography (PPG) signals. To tackle it, self-supervised learning has recently gained attentions; due to the lack of ground truth PPG signals, its performance is however limited. In this paper, we propose a novel self-supervised framework that successfully integrates the popular vision-language models (VLMs) into the remote physiological measurement task. Given a facial video, we first augment its positive and negative video samples with varying rPPG signal frequencies. Next, we introduce a frequency-oriented vision-text pair generation method by carefully creating contrastive spatio-temporal maps from positive and negative samples and designing proper text prompts to describe their relative ratios of signal frequencies. A pre-trained VLM is employed to extract features for these formed vision-text pairs and estimate rPPG signals thereafter. We develop a series of generative and contrastive learning mechanisms to optimize the VLM, including the text-guided visual map reconstruction task, the vision-text contrastive learning task, and the frequency contrastive and ranking task. Overall, our method for the first time adapts VLMs to digest and align the frequency-related knowledge in vision and text modalities. Extensive experiments on four benchmark datasets demonstrate that it significantly outperforms state of the art self-supervised methods.