Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootstrapping a Crosslingual Semantic Parser
Paper and Code
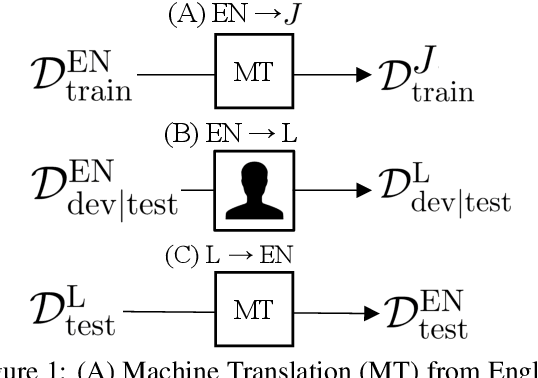

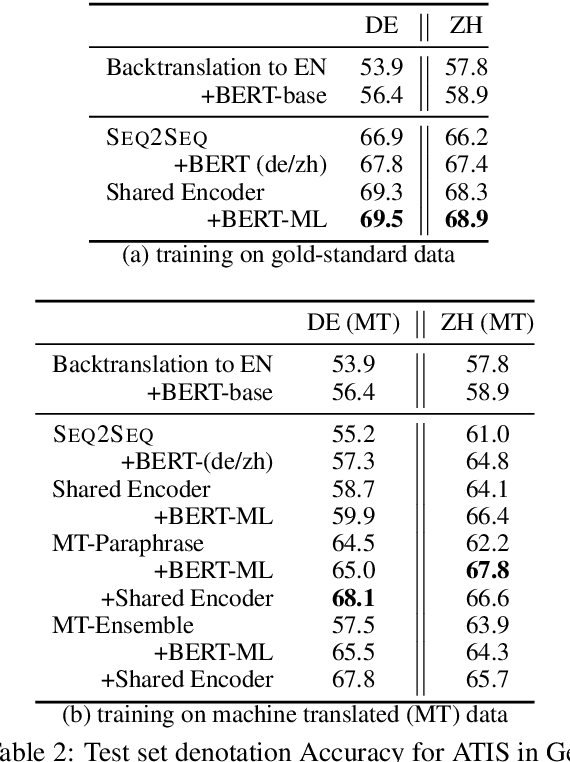
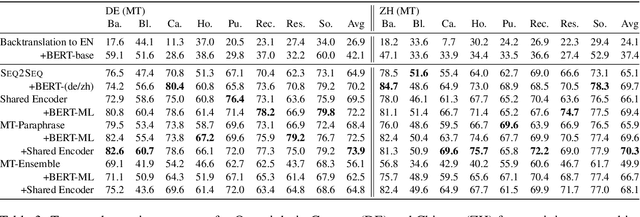
Datasets for semantic parsing scarcely consider languages other than English and professional translation can be prohibitively expensive. In this work, we propose to adapt a semantic parser trained on a single language, such as English, to new languages and multiple domains with minimal annotation. We evaluate if machine translation is an adequate substitute for training data, and extend this to investigate bootstrapping using joint training with English, paraphrasing, and resources such as multilingual BERT. Experimental results on a new version of ATIS and Overnight in German and Chinese indicate that MT can approximate training data in a new language for accurate parsing when augmented with paraphrasing through multiple MT engines.
* Fixing a LaTeX error which swapped the results for DE/ZH
View paper on