 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Adversarial Robustness From The Perspective of Effective Margin Regularization
Paper and Code
Oct 11, 2022
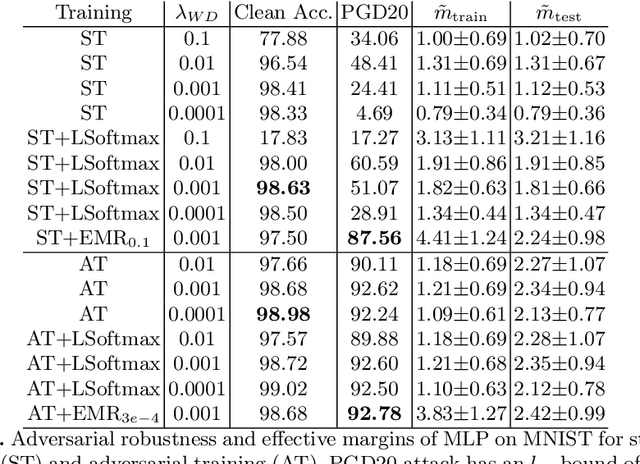
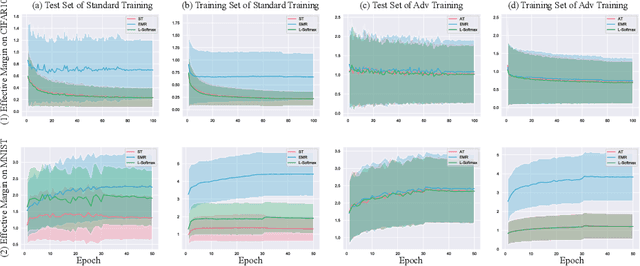
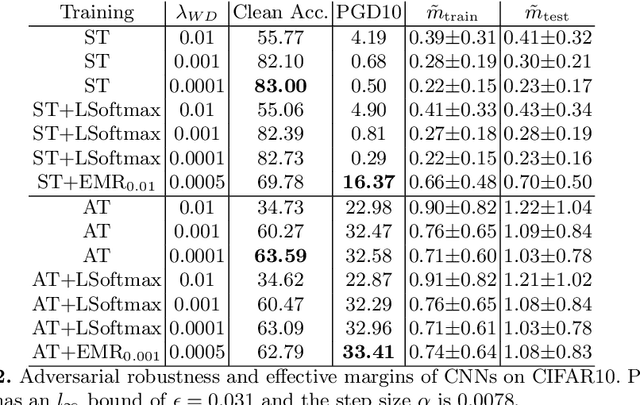
The adversarial vulnerability of deep neural networks (DNNs) has been actively investigated in the past several years. This paper investigates the scale-variant property of cross-entropy loss, which is the most commonly used loss function in classification tasks, and its impact on the effective margin and adversarial robustness of deep neural networks. Since the loss function is not invariant to logit scaling, increasing the effective weight norm will make the loss approach zero and its gradient vanish while the effective margin is not adequately maximized. On typical DNNs, we demonstrate that, if not properly regularized, the standard training does not learn large effective margins and leads to adversarial vulnerability. To maximize the effective margins and learn a robust DNN, we propose to regularize the effective weight norm during training. Our empirical study on feedforward DNNs demonstrates that the proposed effective margin regularization (EMR) learns large effective margins and boosts the adversarial robustness in both standard and adversarial training. On large-scale models, we show that EMR outperforms basic adversarial training, TRADES and two regularization baselines with substantial improvement. Moreover, when combined with several strong adversarial defense methods (MART and MAIL), our EMR further boosts the robustness.