 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting a Model Zoo for Multi-Task and Continual Learning
Paper and Code
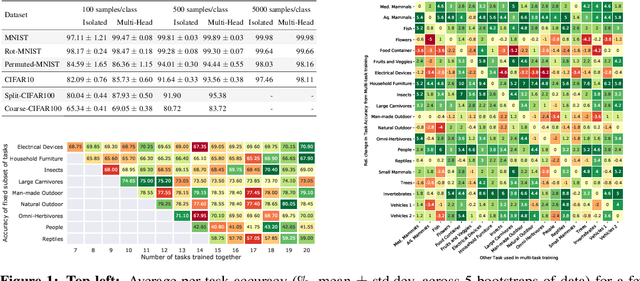
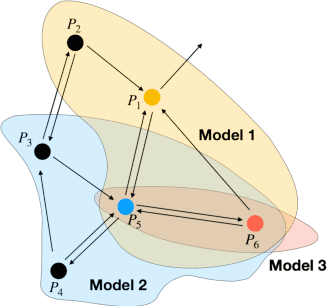
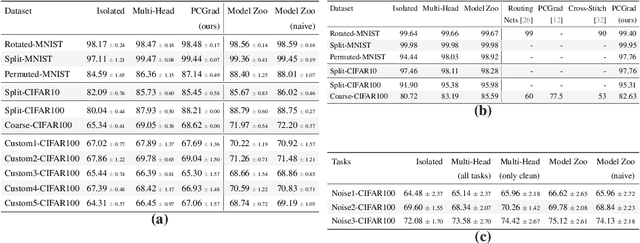
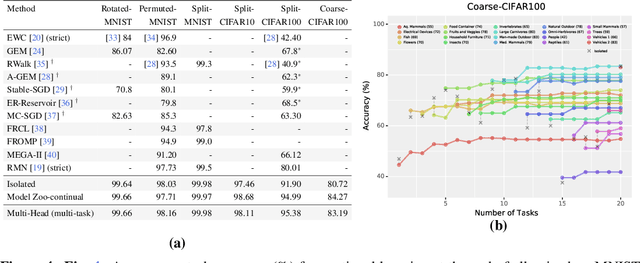
Leveraging data from multiple tasks, either all at once, or incrementally, to learn one model is an idea that lies at the heart of multi-task and continual learning methods. Ideally, such a model predicts each task more accurately than if the task were trained in isolation. We show using tools in statistical learning theory (i) how tasks can compete for capacity, i.e., including a particular task can deteriorate the accuracy on a given task, and (ii) that the ideal set of tasks that one should train together in order to perform well on a given task is different for different tasks. We develop methods to discover such competition in typical benchmark datasets which suggests that the prevalent practice of training with all tasks leaves performance on the table. This motivates our "Model Zoo", which is a boosting-based algorithm that builds an ensemble of models, each of which is very small, and it is trained on a smaller set of tasks. Model Zoo achieves large gains in prediction accuracy compared to state-of-the-art methods across a variety of existing benchmarks in multi-task and continual learning, as well as more challenging ones of our creation. We also show that even a model trained independently on all tasks outperforms all existing multi-task and continual learning methods.