Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosted Off-Policy Learning
Paper and Code
Aug 01, 2022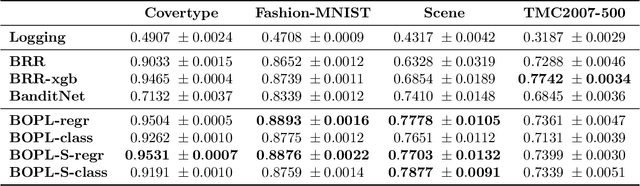
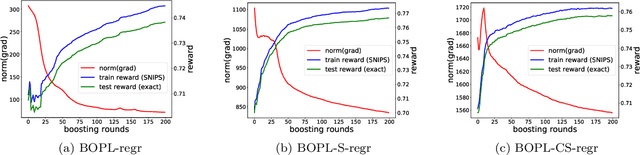


We investigate boosted ensemble models for off-policy learning from logged bandit feedback. Toward this goal, we propose a new boosting algorithm that directly optimizes an estimate of the policy's expected reward. We analyze this algorithm and prove that the empirical risk decreases (possibly exponentially fast) with each round of boosting, provided a "weak" learning condition is satisfied. We further show how the base learner reduces to standard supervised learning problems. Experiments indicate that our algorithm can outperform deep off-policy learning and methods that simply regress on the observed rewards, thereby demonstrating the benefits of both boosting and choosing the right learning objective.
View paper on