 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOBA: Byzantine-Robust Federated Learning with Label Skewness
Paper and Code
Aug 27, 2022
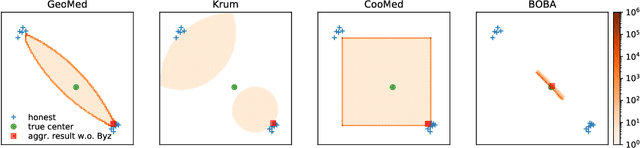


In federated learning, most existing techniques for robust aggregation against Byzantine attacks are designed for the IID setting, i.e., the data distributions for clients are independent and identically distributed. In this paper, we address label skewness, a more realistic and challenging non-IID setting, where each client only has access to a few classes of data. In this setting, state-of-the-art techniques suffer from selection bias, leading to significant performance drop for particular classes; they are also more vulnerable to Byzantine attacks due to the increased deviation among gradients of honest clients. To address these limitations, we propose an efficient two-stage method named BOBA. Theoretically, we prove the convergence of BOBA with an error of optimal order. Empirically, we verify the superior unbiasedness and robustness of BOBA across a wide range of models and data sets against various baselines.