 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlock Layer Decomposition schemes for training Deep Neural Networks
Paper and Code
Mar 18, 2020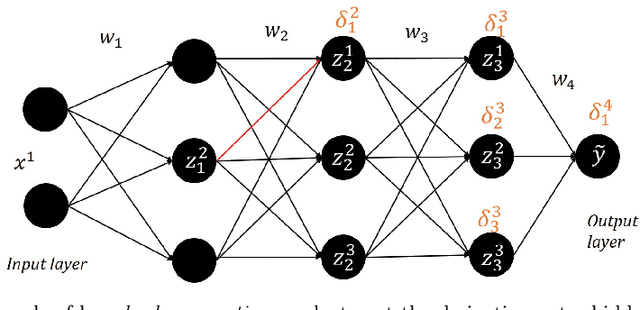
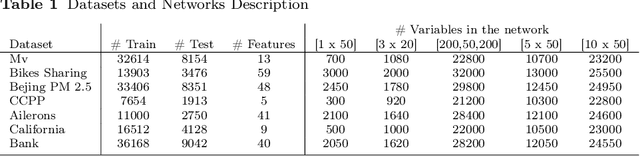

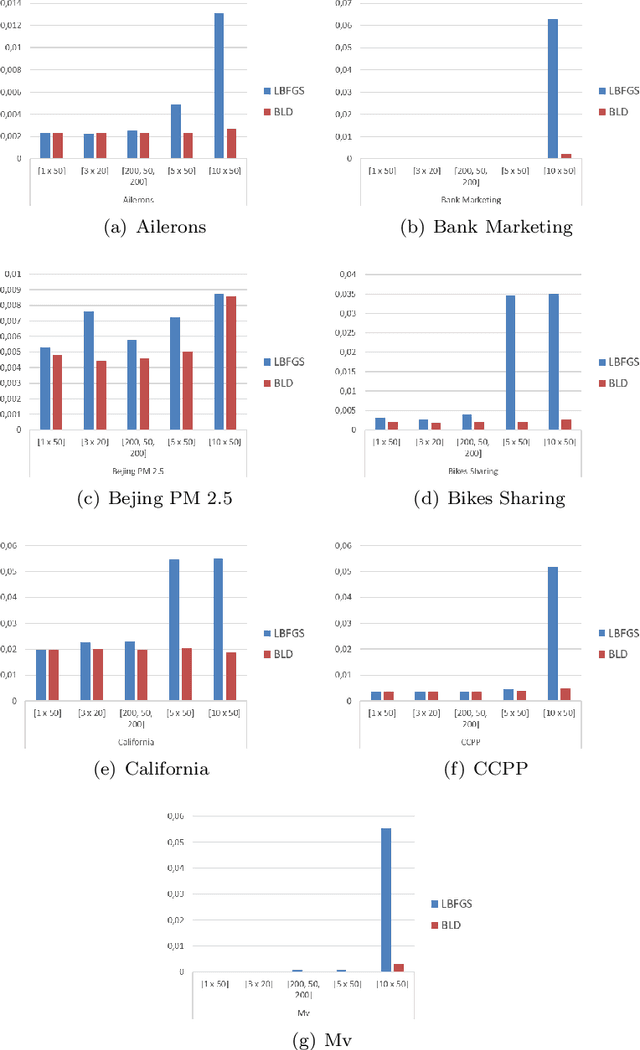
Deep Feedforward Neural Networks' (DFNNs) weights estimation relies on the solution of a very large nonconvex optimization problem that may have many local (no global) minimizers, saddle points and large plateaus. As a consequence, optimization algorithms can be attracted toward local minimizers which can lead to bad solutions or can slow down the optimization process. Furthermore, the time needed to find good solutions to the training problem depends on both the number of samples and the number of variables. In this work, we show how Block Coordinate Descent (BCD) methods can be applied to improve performance of state-of-the-art algorithms by avoiding bad stationary points and flat regions. We first describe a batch BCD method ables to effectively tackle the network's depth and then we further extend the algorithm proposing a \textit{minibatch} BCD framework able to scale with respect to both the number of variables and the number of samples by embedding a BCD approach into a minibatch framework. By extensive numerical results on standard datasets for several architecture networks, we show how the application of BCD methods to the training phase of DFNNs permits to outperform standard batch and minibatch algorithms leading to an improvement on both the training phase and the generalization performance of the networks.