 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlended Latent Diffusion
Paper and Code
Jun 06, 2022


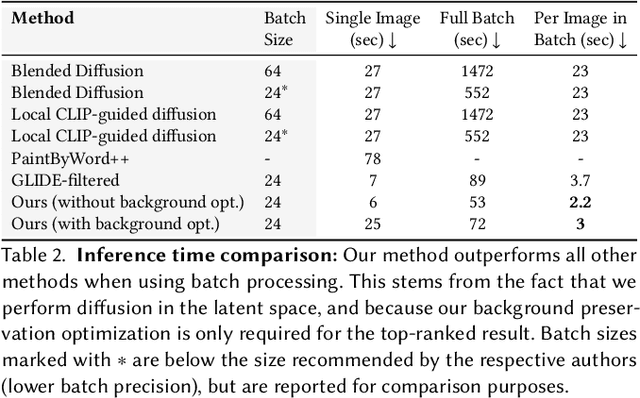
The tremendous progress in neural image generation, coupled with the emergence of seemingly omnipotent vision-language models has finally enabled text-based interfaces for creating and editing images. Handling generic images requires a diverse underlying generative model, hence the latest works utilize diffusion models, which were shown to surpass GANs in terms of diversity. One major drawback of diffusion models, however, is their relatively slow inference time. In this paper, we present an accelerated solution to the task of local text-driven editing of generic images, where the desired edits are confined to a user-provided mask. Our solution leverages a recent text-to-image Latent Diffusion Model (LDM), which speeds up diffusion by operating in a lower-dimensional latent space. We first convert the LDM into a local image editor by incorporating Blended Diffusion into it. Next we propose an optimization-based solution for the inherent inability of this LDM to accurately reconstruct images. Finally, we address the scenario of performing local edits using thin masks. We evaluate our method against the available baselines both qualitatively and quantitatively and demonstrate that in addition to being faster, our method achieves better precision than the baselines while mitigating some of their artifacts. Project page is available at https://omriavrahami.com/blended-latent-diffusion-page/