 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlack-Box Segmentation of Electronic Medical Records
Paper and Code
Sep 29, 2024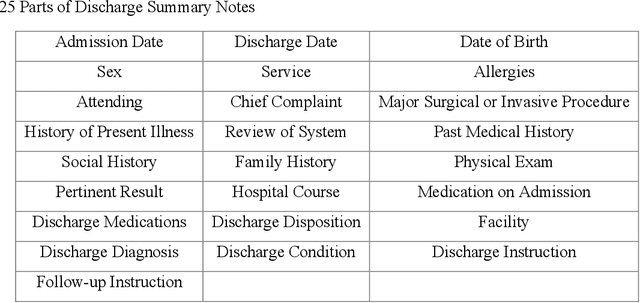
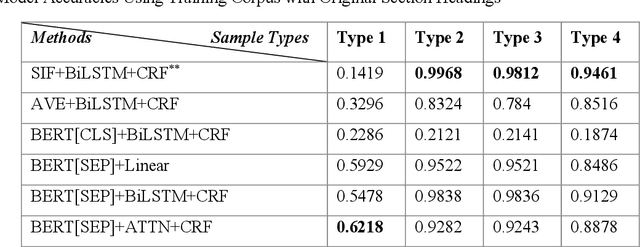
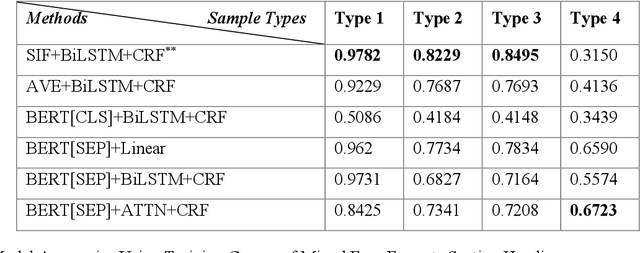
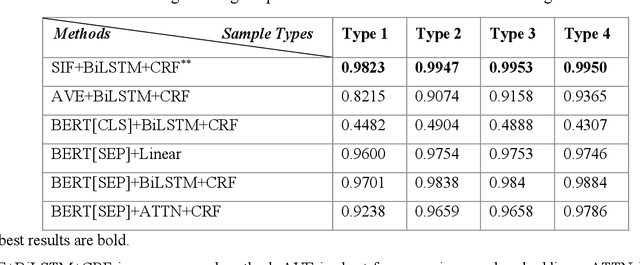
Electronic medical records (EMRs) contain the majority of patients' healthcare details. It is an abundant resource for developing an automatic healthcare system. Most of the natural language processing (NLP) studies on EMR processing, such as concept extraction, are adversely affected by the inaccurate segmentation of EMR sections. At the same time, not enough attention has been given to the accurate sectioning of EMRs. The information that may occur in section structures is unvalued. This work focuses on the segmentation of EMRs and proposes a black-box segmentation method using a simple sentence embedding model and neural network, along with a proper training method. To achieve universal adaptivity, we train our model on the dataset with different section headings formats. We compare several advanced deep learning-based NLP methods, and our method achieves the best segmentation accuracies (above 98%) on various test data with a proper training corpus.