 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlack-box Backdoor Defense via Zero-shot Image Purification
Paper and Code
Mar 21, 2023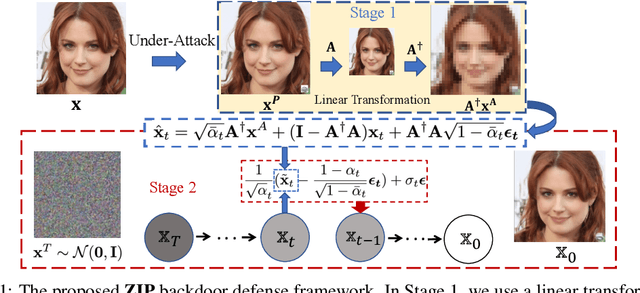
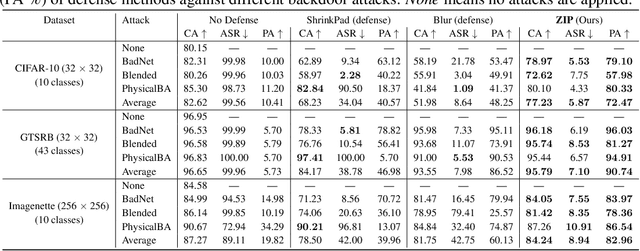


Backdoor attacks inject poisoned data into the training set, resulting in misclassification of the poisoned samples during model inference. Defending against such attacks is challenging, especially in real-world black-box settings where only model predictions are available. In this paper, we propose a novel backdoor defense framework that can effectively defend against various attacks through zero-shot image purification (ZIP). Our proposed framework can be applied to black-box models without requiring any internal information about the poisoned model or any prior knowledge of the clean/poisoned samples. Our defense framework involves a two-step process. First, we apply a linear transformation on the poisoned image to destroy the trigger pattern. Then, we use a pre-trained diffusion model to recover the missing semantic information removed by the transformation. In particular, we design a new reverse process using the transformed image to guide the generation of high-fidelity purified images, which can be applied in zero-shot settings. We evaluate our ZIP backdoor defense framework on multiple datasets with different kinds of attacks. Experimental results demonstrate the superiority of our ZIP framework compared to state-of-the-art backdoor defense baselines. We believe that our results will provide valuable insights for future defense methods for black-box models.