 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBilingual alignment transfers to multilingual alignment for unsupervised parallel text mining
Paper and Code
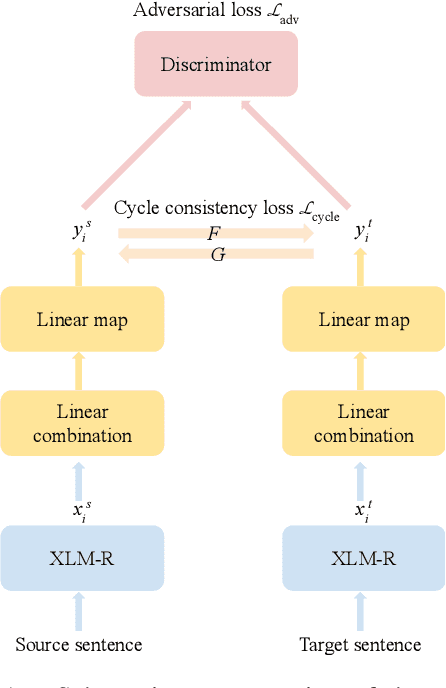

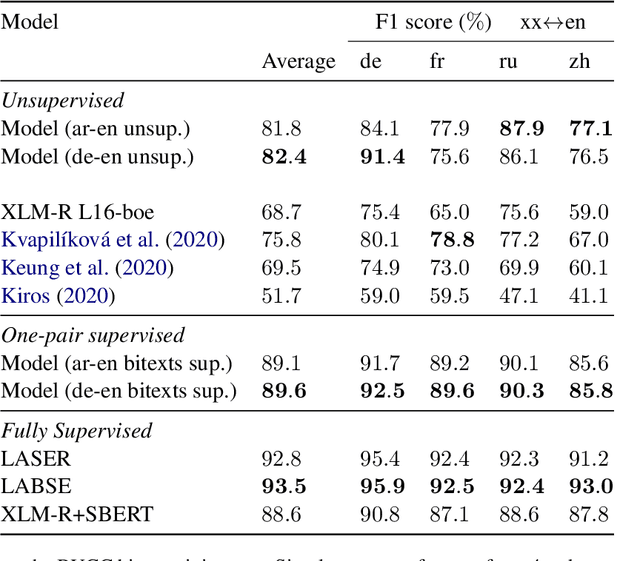
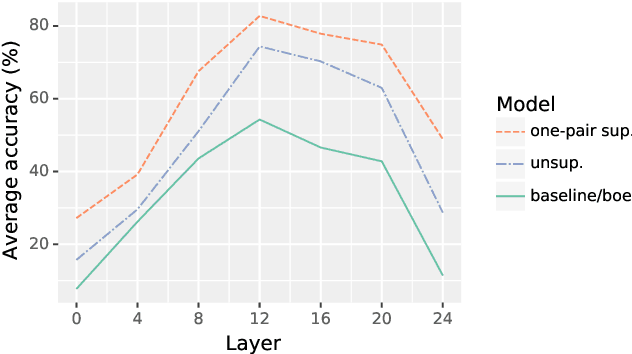
This work presents methods for learning cross-lingual sentence representations using paired or unpaired bilingual texts. We hypothesize that the cross-lingual alignment strategy is transferable, and therefore a model trained to align only two languages can encode multilingually more aligned representations. And such transfer from bilingual alignment to multilingual alignment is a dual-pivot transfer from two pivot languages to other language pairs. To study this theory, we train an unsupervised model with unpaired sentences and another single-pair supervised model with bitexts, both based on the unsupervised language model XLM-R. The experiments evaluate the models as universal sentence encoders on the task of unsupervised bitext mining on two datasets, where the unsupervised model reaches the state of the art of unsupervised retrieval, and the alternative single-pair supervised model approaches the performance of multilingually supervised models. The results suggest that bilingual training techniques as proposed can be applied to get sentence representations with higher multilingual alignment.