Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBidirectional Multiscale Feature Aggregation for Speaker Verification
Paper and Code
Apr 01, 2021
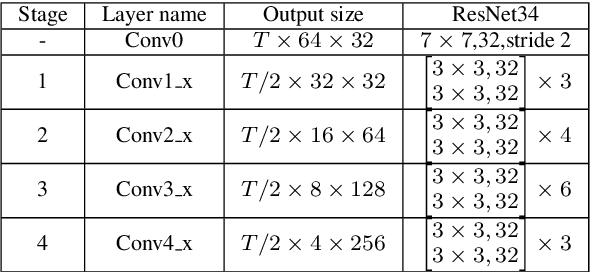
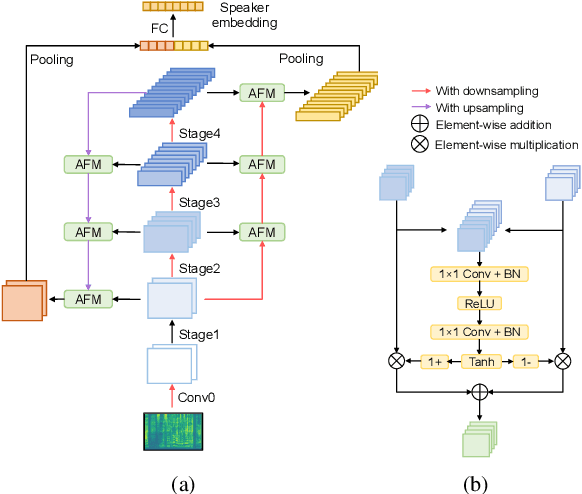

In this paper, we propose a novel bidirectional multiscale feature aggregation (BMFA) network with attentional fusion modules for text-independent speaker verification. The feature maps from different stages of the backbone network are iteratively combined and refined in both a bottom-up and top-down manner. Furthermore, instead of simple concatenation or element-wise addition of feature maps from different stages, an attentional fusion module is designed to compute the fusion weights. Experiments are conducted on the NIST SRE16 and VoxCeleb1 datasets. The experimental results demonstrate the effectiveness of the bidirectional aggregation strategy and show that the proposed attentional fusion module can further improve the performance.
View paper on