 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiased Importance Sampling for Deep Neural Network Training
Paper and Code
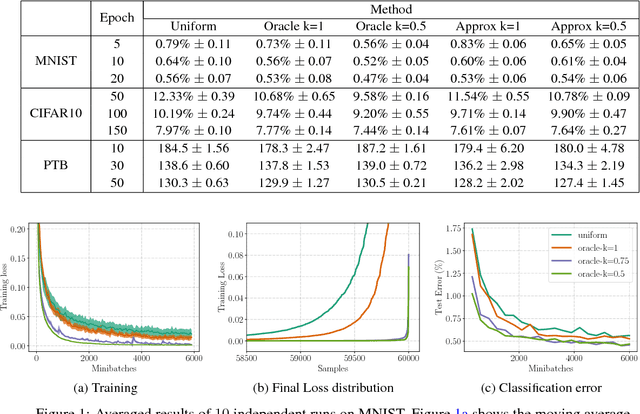
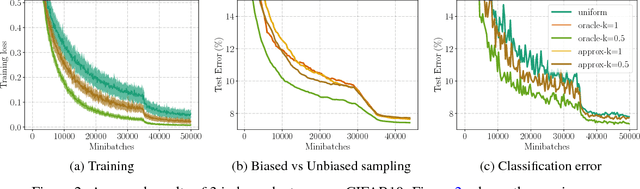
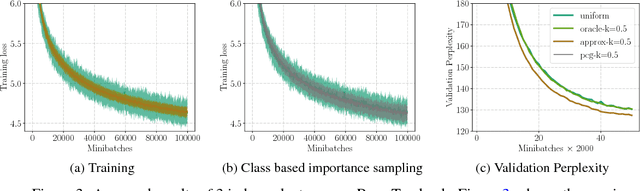
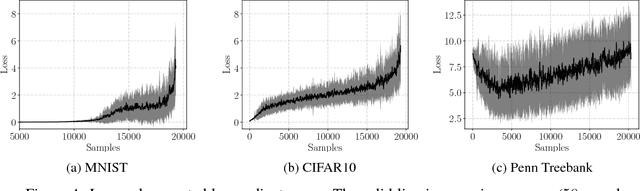
Importance sampling has been successfully used to accelerate stochastic optimization in many convex problems. However, the lack of an efficient way to calculate the importance still hinders its application to Deep Learning. In this paper, we show that the loss value can be used as an alternative importance metric, and propose a way to efficiently approximate it for a deep model, using a small model trained for that purpose in parallel. This method allows in particular to utilize a biased gradient estimate that implicitly optimizes a soft max-loss, and leads to better generalization performance. While such method suffers from a prohibitively high variance of the gradient estimate when using a standard stochastic optimizer, we show that when it is combined with our sampling mechanism, it results in a reliable procedure. We showcase the generality of our method by testing it on both image classification and language modeling tasks using deep convolutional and recurrent neural networks. In particular, our method results in 30% faster training of a CNN for CIFAR10 than when using uniform sampling.