 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias Mimicking: A Simple Sampling Approach for Bias Mitigation
Paper and Code
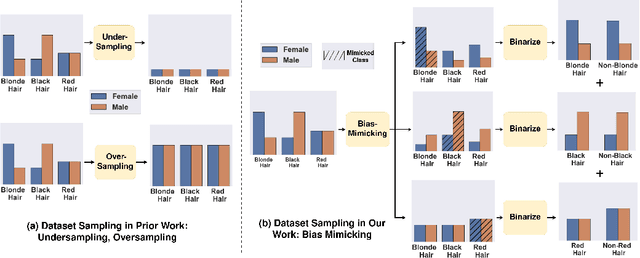
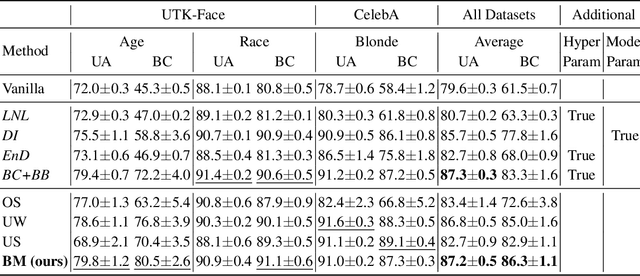
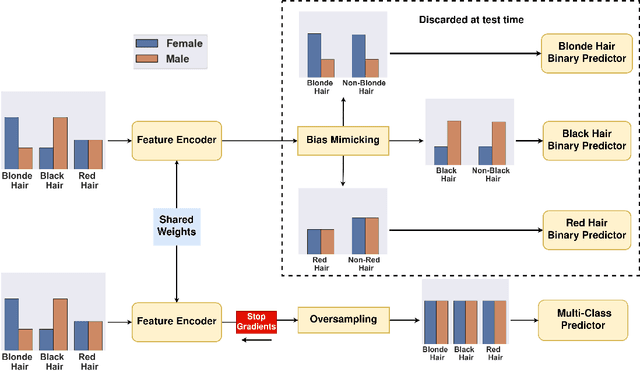
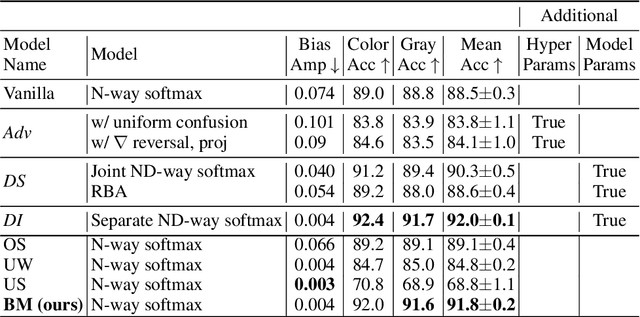
Prior work has shown that Visual Recognition datasets frequently under-represent sensitive groups (\eg Female) within a category (\eg Programmers). This dataset bias can lead to models that learn spurious correlations between class labels and sensitive attributes such as age, gender, or race. Most of the recent methods that address this problem require significant architectural changes or expensive hyper-parameter tuning. Alternatively, data re-sampling baselines from the class imbalance literature (\eg Undersampling, Upweighting), which can often be implemented in a single line of code and often have no hyperparameters, offer a cheaper and more efficient solution. However, we found that some of these baselines were missing from recent bias mitigation benchmarks. In this paper, we show that these simple methods are strikingly competitive with state-of-the-art bias mitigation methods on many datasets. Furthermore, we improve these methods by introducing a new class conditioned sampling method: Bias Mimicking. In cases where the baseline dataset re-sampling methods do not perform well, Bias Mimicking effectively bridges the performance gap and improves the total averaged accuracy of under-represented subgroups by over $3\%$ compared to prior work.