 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Narrative Description: Generating Poetry from Images by Multi-Adversarial Training
Paper and Code

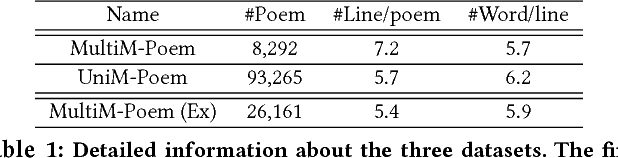
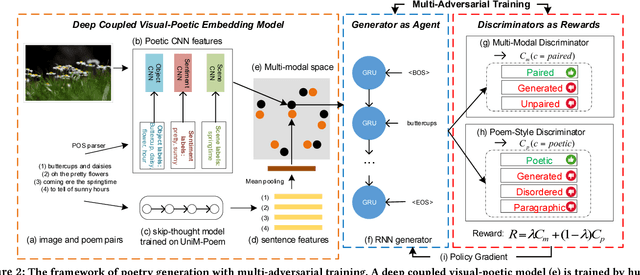

Automatic generation of natural language from images has attracted extensive attention. In this paper, we take one step further to investigate generation of poetic language (with multiple lines) to an image for automatic poetry creation. This task involves multiple challenges, including discovering poetic clues from the image (e.g., hope from green), and generating poems to satisfy both relevance to the image and poeticness in language level. To solve the above challenges, we formulate the task of poem generation into two correlated sub-tasks by multi-adversarial training via policy gradient, through which the cross-modal relevance and poetic language style can be ensured. To extract poetic clues from images, we propose to learn a deep coupled visual-poetic embedding, in which the poetic representation from objects, sentiments and scenes in an image can be jointly learned. Two discriminative networks are further introduced to guide the poem generation, including a multi-modal discriminator and a poem-style discriminator. To facilitate the research, we have released two poem datasets by human annotators with two distinct properties: 1) the first human annotated image-to-poem pair dataset (with 8,292 pairs in total), and 2) to-date the largest public English poem corpus dataset (with 92,265 different poems in total). Extensive experiments are conducted with 8K images, among which 1.5K image are randomly picked for evaluation. Both objective and subjective evaluations show the superior performances against the state-of-the-art methods for poem generation from images. Turing test carried out with over 500 human subjects, among which 30 evaluators are poetry experts, demonstrates the effectiveness of our approach.