 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Instructional Videos: Probing for More Diverse Visual-Textual Grounding on YouTube
Paper and Code
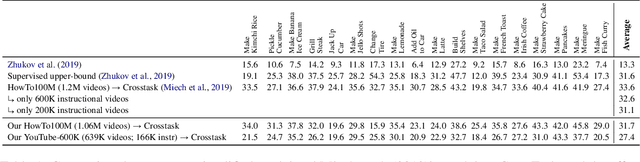
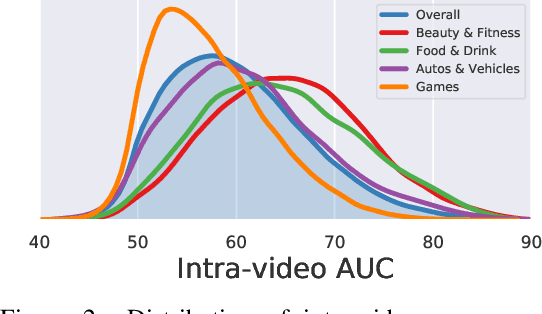
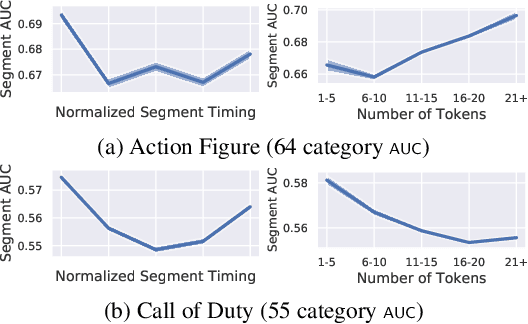
Pretraining from unlabelled web videos has quickly become the de-facto means of achieving high performance on many video understanding tasks. Features are learned via prediction of grounded relationships between visual content and automatic speech recognition (ASR) tokens. However, prior pretraining work has been limited to only instructional videos, a domain that, a priori, we expect to be relatively "easy:" speakers in instructional videos will often reference the literal objects/actions being depicted. Because instructional videos make up only a fraction of the web's diverse video content, we ask: can similar models be trained on broader corpora? And, if so, what types of videos are "grounded" and what types are not? We examine the diverse YouTube8M corpus, first verifying that it contains many non-instructional videos via crowd labeling. We pretrain a representative model on YouTube8M and study its success and failure cases. We find that visual-textual grounding is indeed possible across previously unexplored video categories, and that pretraining on a more diverse set still results in representations that generalize to both non-instructional and instructional domains.