 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Human-Level Accuracy: Computational Challenges in Deep Learning
Paper and Code
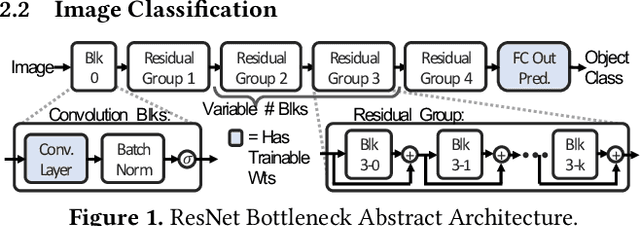
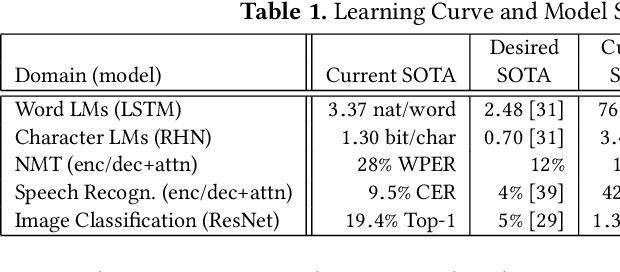
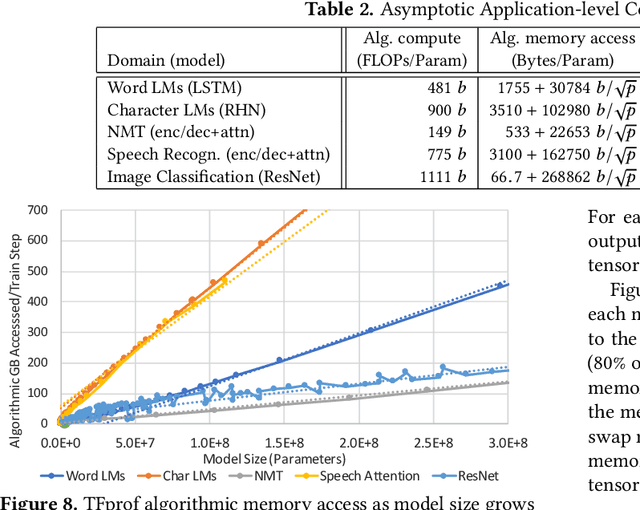
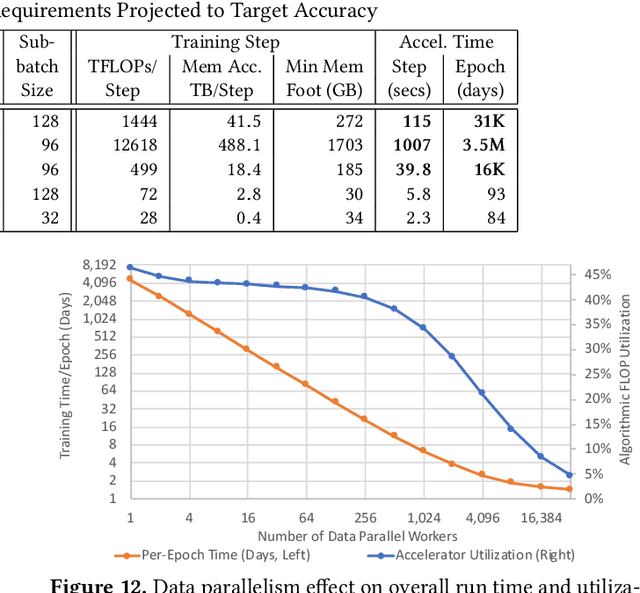
Deep learning (DL) research yields accuracy and product improvements from both model architecture changes and scale: larger data sets and models, and more computation. For hardware design, it is difficult to predict DL model changes. However, recent prior work shows that as dataset sizes grow, DL model accuracy and model size grow predictably. This paper leverages the prior work to project the dataset and model size growth required to advance DL accuracy beyond human-level, to frontier targets defined by machine learning experts. Datasets will need to grow $33$--$971 \times$, while models will need to grow $6.6$--$456\times$ to achieve target accuracies. We further characterize and project the computational requirements to train these applications at scale. Our characterization reveals an important segmentation of DL training challenges for recurrent neural networks (RNNs) that contrasts with prior studies of deep convolutional networks. RNNs will have comparatively moderate operational intensities and very large memory footprint requirements. In contrast to emerging accelerator designs, large-scale RNN training characteristics suggest designs with significantly larger memory capacity and on-chip caches.