 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Cartesian Representations for Local Descriptors
Paper and Code
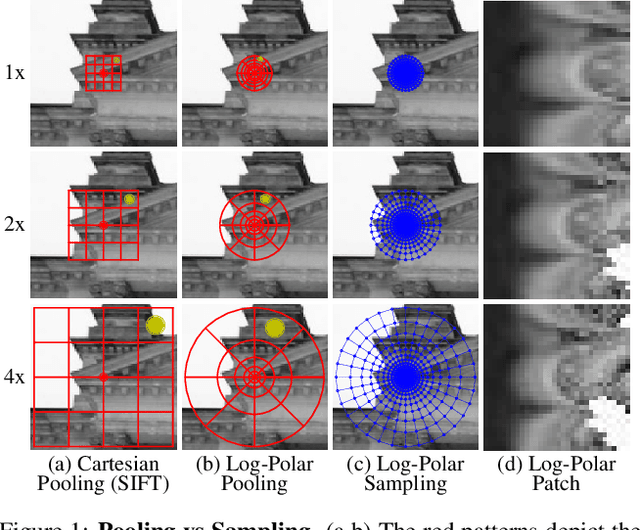
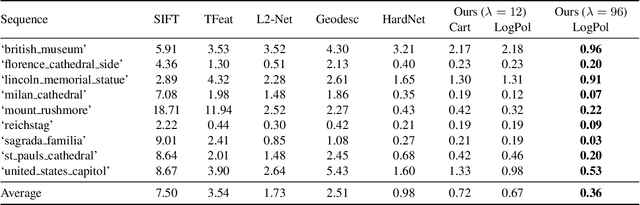

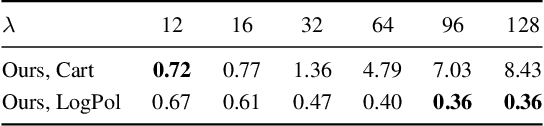
The dominant approach for learning local patch descriptors relies on small image regions whose scale must be properly estimated a priori by a keypoint detector. In other words, if two patches are not in correspondence, their descriptors will not match. A strategy often used to alleviate this problem is to "pool" the pixel-wise features over log-polar regions, rather than regularly spaced ones. By contrast, we propose to extract the "support region" directly with a log-polar sampling scheme. We show that this provides us with a better representation by simultaneously oversampling the immediate neighbourhood of the point and undersampling regions far away from it. We demonstrate that this representation is particularly amenable to learning descriptors with deep networks. Our models can match descriptors across a much wider range of scales than was possible before, and also leverage much larger support regions without suffering from occlusions. We report state-of-the-art results on three different datasets.