 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond a Pre-Trained Object Detector: Cross-Modal Textual and Visual Context for Image Captioning
Paper and Code
May 09, 2022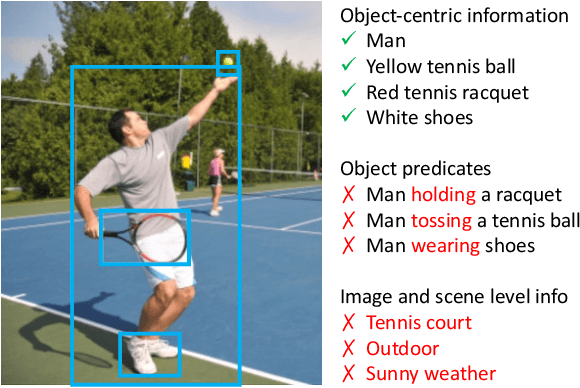
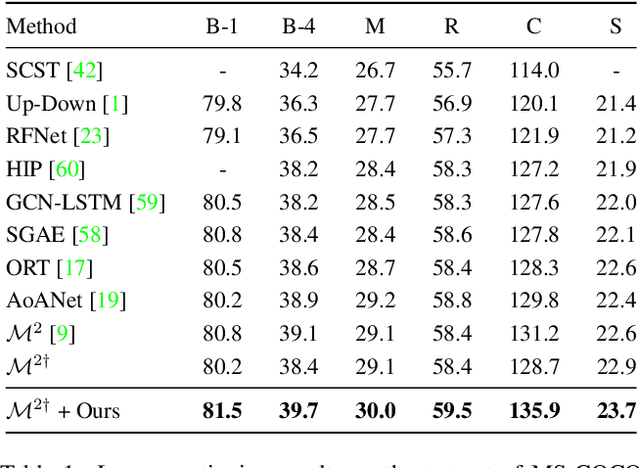
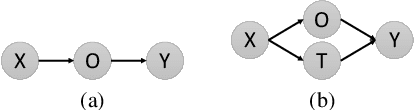
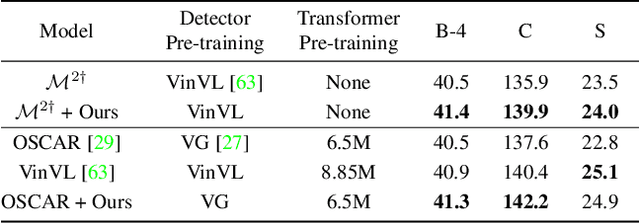
Significant progress has been made on visual captioning, largely relying on pre-trained features and later fixed object detectors that serve as rich inputs to auto-regressive models. A key limitation of such methods, however, is that the output of the model is conditioned only on the object detector's outputs. The assumption that such outputs can represent all necessary information is unrealistic, especially when the detector is transferred across datasets. In this work, we reason about the graphical model induced by this assumption, and propose to add an auxiliary input to represent missing information such as object relationships. We specifically propose to mine attributes and relationships from the Visual Genome dataset and condition the captioning model on them. Crucially, we propose (and show to be important) the use of a multi-modal pre-trained model (CLIP) to retrieve such contextual descriptions. Further, object detector models are frozen and do not have sufficient richness to allow the captioning model to properly ground them. As a result, we propose to condition both the detector and description outputs on the image, and show qualitatively and quantitatively that this can improve grounding. We validate our method on image captioning, perform thorough analyses of each component and importance of the pre-trained multi-modal model, and demonstrate significant improvements over the current state of the art, specifically +7.5% in CIDEr and +1.3% in BLEU-4 metrics.