 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBest Response Shaping
Paper and Code
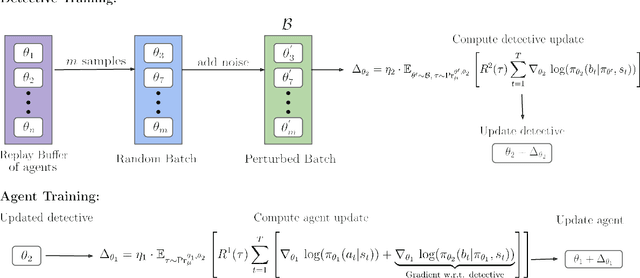
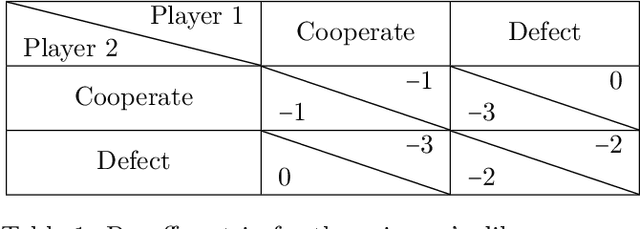
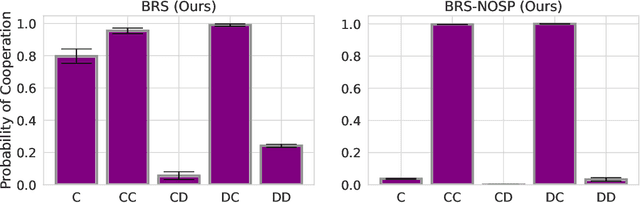
We investigate the challenge of multi-agent deep reinforcement learning in partially competitive environments, where traditional methods struggle to foster reciprocity-based cooperation. LOLA and POLA agents learn reciprocity-based cooperative policies by differentiation through a few look-ahead optimization steps of their opponent. However, there is a key limitation in these techniques. Because they consider a few optimization steps, a learning opponent that takes many steps to optimize its return may exploit them. In response, we introduce a novel approach, Best Response Shaping (BRS), which differentiates through an opponent approximating the best response, termed the "detective." To condition the detective on the agent's policy for complex games we propose a state-aware differentiable conditioning mechanism, facilitated by a question answering (QA) method that extracts a representation of the agent based on its behaviour on specific environment states. To empirically validate our method, we showcase its enhanced performance against a Monte Carlo Tree Search (MCTS) opponent, which serves as an approximation to the best response in the Coin Game. This work expands the applicability of multi-agent RL in partially competitive environments and provides a new pathway towards achieving improved social welfare in general sum games.