 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBest-of-Both-Worlds Linear Contextual Bandits
Paper and Code
Dec 27, 2023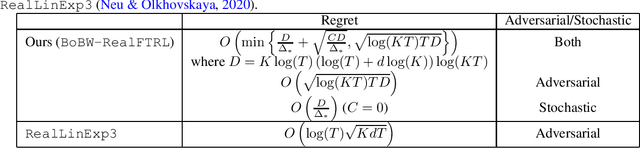
This study investigates the problem of $K$-armed linear contextual bandits, an instance of the multi-armed bandit problem, under an adversarial corruption. At each round, a decision-maker observes an independent and identically distributed context and then selects an arm based on the context and past observations. After selecting an arm, the decision-maker incurs a loss corresponding to the selected arm. The decision-maker aims to minimize the cumulative loss over the trial. The goal of this study is to develop a strategy that is effective in both stochastic and adversarial environments, with theoretical guarantees. We first formulate the problem by introducing a novel setting of bandits with adversarial corruption, referred to as the contextual adversarial regime with a self-bounding constraint. We assume linear models for the relationship between the loss and the context. Then, we propose a strategy that extends the RealLinExp3 by Neu & Olkhovskaya (2020) and the Follow-The-Regularized-Leader (FTRL). The regret of our proposed algorithm is shown to be upper-bounded by $O\left(\min\left\{\frac{(\log(T))^3}{\Delta_{*}} + \sqrt{\frac{C(\log(T))^3}{\Delta_{*}}},\ \ \sqrt{T}(\log(T))^2\right\}\right)$, where $T \in\mathbb{N}$ is the number of rounds, $\Delta_{*} > 0$ is the constant minimum gap between the best and suboptimal arms for any context, and $C\in[0, T] $ is an adversarial corruption parameter. This regret upper bound implies $O\left(\frac{(\log(T))^3}{\Delta_{*}}\right)$ in a stochastic environment and by $O\left( \sqrt{T}(\log(T))^2\right)$ in an adversarial environment. We refer to our strategy as the Best-of-Both-Worlds (BoBW) RealFTRL, due to its theoretical guarantees in both stochastic and adversarial regimes.