Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERT & Family Eat Word Salad: Experiments with Text Understanding
Paper and Code



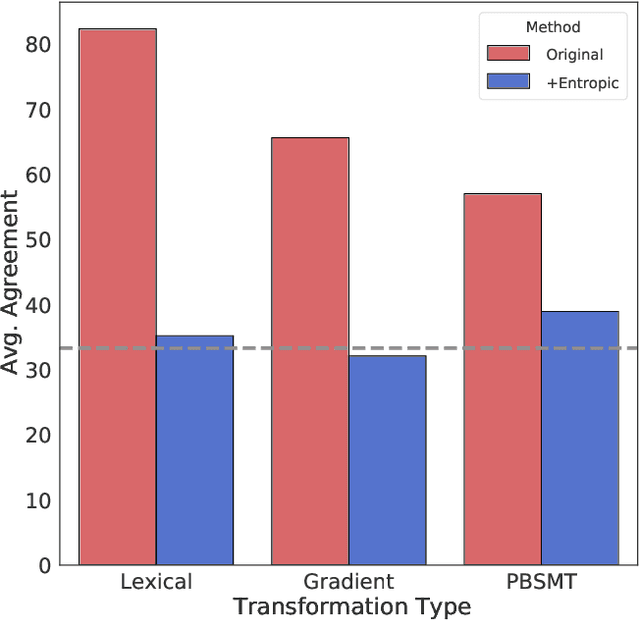
In this paper, we study the response of large models from the BERT family to incoherent inputs that should confuse any model that claims to understand natural language. We define simple heuristics to construct such examples. Our experiments show that state-of-the-art models consistently fail to recognize them as ill-formed, and instead produce high confidence predictions on them. Finally, we show that if models are explicitly trained to recognize invalid inputs, they can be robust to such attacks without a drop in performance.
* Accepted at AAAI 2021
View paper on