 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERT based sentiment analysis: A software engineering perspective
Paper and Code
Jun 28, 2021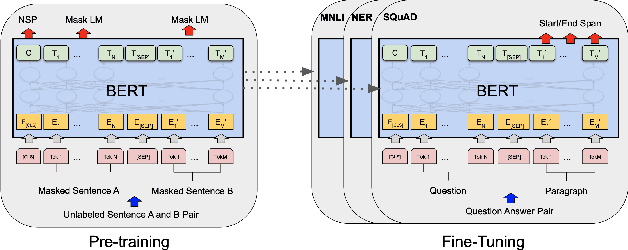

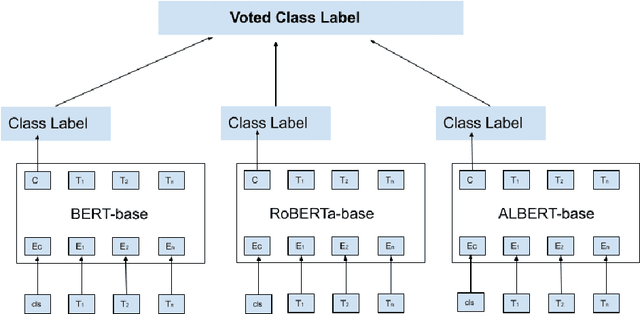

Sentiment analysis can provide a suitable lead for the tools used in software engineering along with the API recommendation systems and relevant libraries to be used. In this context, the existing tools like SentiCR, SentiStrength-SE, etc. exhibited low f1-scores that completely defeats the purpose of deployment of such strategies, thereby there is enough scope for performance improvement. Recent advancements show that transformer based pre-trained models (e.g., BERT, RoBERTa, ALBERT, etc.) have displayed better results in the text classification task. Following this context, the present research explores different BERT-based models to analyze the sentences in GitHub comments, Jira comments, and Stack Overflow posts. The paper presents three different strategies to analyse BERT based model for sentiment analysis, where in the first strategy the BERT based pre-trained models are fine-tuned; in the second strategy an ensemble model is developed from BERT variants, and in the third strategy a compressed model (Distil BERT) is used. The experimental results show that the BERT based ensemble approach and the compressed BERT model attain improvements by 6-12% over prevailing tools for the F1 measure on all three datasets.