 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Floworks against OpenAI & Anthropic: A Novel Framework for Enhanced LLM Function Calling
Paper and Code
Oct 23, 2024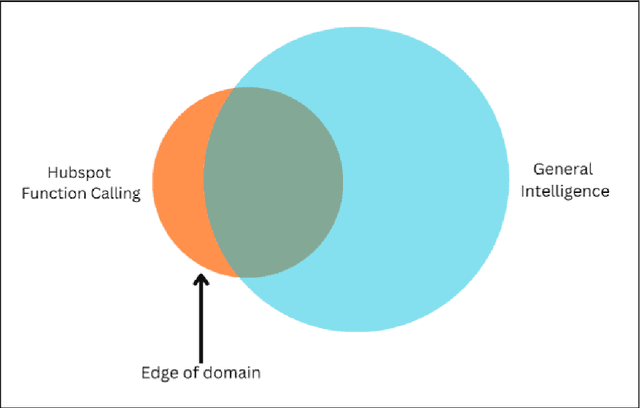

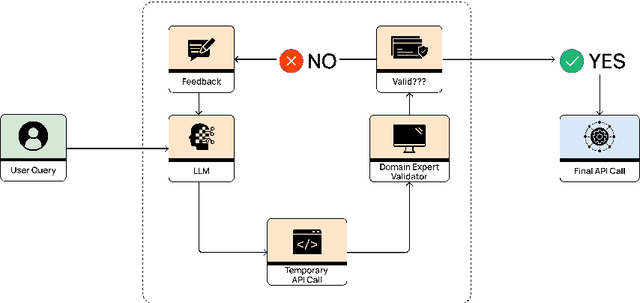

Large Language Models (LLMs) have shown remarkable capabilities in various domains, yet their economic impact has been limited by challenges in tool use and function calling. This paper introduces ThorV2, a novel architecture that significantly enhances LLMs' function calling abilities. We develop a comprehensive benchmark focused on HubSpot CRM operations to evaluate ThorV2 against leading models from OpenAI and Anthropic. Our results demonstrate that ThorV2 outperforms existing models in accuracy, reliability, latency, and cost efficiency for both single and multi-API calling tasks. We also show that ThorV2 is far more reliable and scales better to multistep tasks compared to traditional models. Our work offers the tantalizing possibility of more accurate function-calling compared to today's best-performing models using significantly smaller LLMs. These advancements have significant implications for the development of more capable AI assistants and the broader application of LLMs in real-world scenarios.