 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Algorithmic Bias in Face Recognition: An Experimental Approach Using Synthetic Faces and Human Evaluation
Paper and Code
Aug 10, 2023

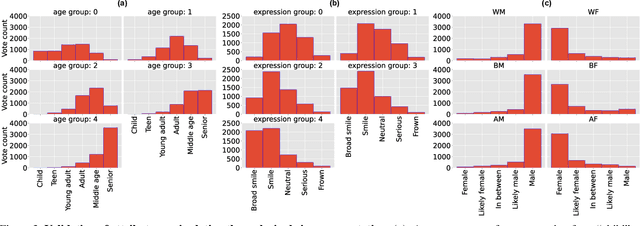
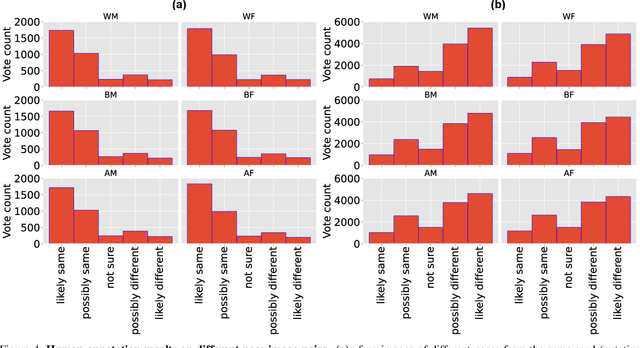
We propose an experimental method for measuring bias in face recognition systems. Existing methods to measure bias depend on benchmark datasets that are collected in the wild and annotated for protected (e.g., race, gender) and non-protected (e.g., pose, lighting) attributes. Such observational datasets only permit correlational conclusions, e.g., "Algorithm A's accuracy is different on female and male faces in dataset X.". By contrast, experimental methods manipulate attributes individually and thus permit causal conclusions, e.g., "Algorithm A's accuracy is affected by gender and skin color." Our method is based on generating synthetic faces using a neural face generator, where each attribute of interest is modified independently while leaving all other attributes constant. Human observers crucially provide the ground truth on perceptual identity similarity between synthetic image pairs. We validate our method quantitatively by evaluating race and gender biases of three research-grade face recognition models. Our synthetic pipeline reveals that for these algorithms, accuracy is lower for Black and East Asian population subgroups. Our method can also quantify how perceptual changes in attributes affect face identity distances reported by these models. Our large synthetic dataset, consisting of 48,000 synthetic face image pairs (10,200 unique synthetic faces) and 555,000 human annotations (individual attributes and pairwise identity comparisons) is available to researchers in this important area.