 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehavioral Priors and Dynamics Models: Improving Performance and Domain Transfer in Offline RL
Paper and Code
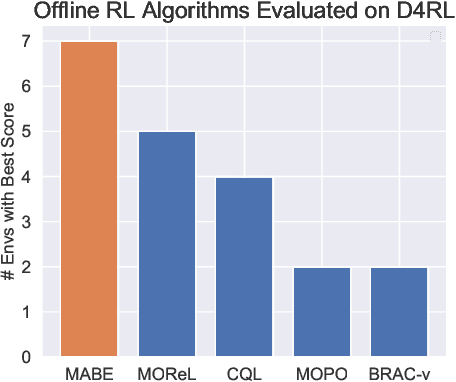

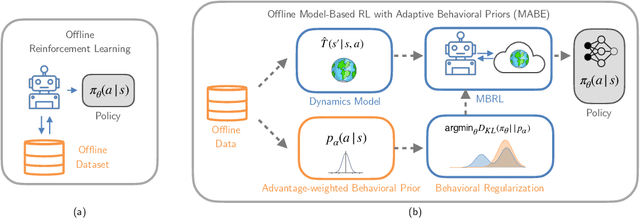

Offline Reinforcement Learning (RL) aims to extract near-optimal policies from imperfect offline data without additional environment interactions. Extracting policies from diverse offline datasets has the potential to expand the range of applicability of RL by making the training process safer, faster, and more streamlined. We investigate how to improve the performance of offline RL algorithms, its robustness to the quality of offline data, as well as its generalization capabilities. To this end, we introduce Offline Model-based RL with Adaptive Behavioral Priors (MABE). Our algorithm is based on the finding that dynamics models, which support within-domain generalization, and behavioral priors, which support cross-domain generalization, are complementary. When combined together, they substantially improve the performance and generalization of offline RL policies. In the widely studied D4RL offline RL benchmark, we find that MABE achieves higher average performance compared to prior model-free and model-based algorithms. In experiments that require cross-domain generalization, we find that MABE outperforms prior methods. Our website is available at https://sites.google.com/berkeley.edu/mabe .