 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian System ID: Optimal management of parameter, model, and measurement uncertainty
Paper and Code
Mar 04, 2020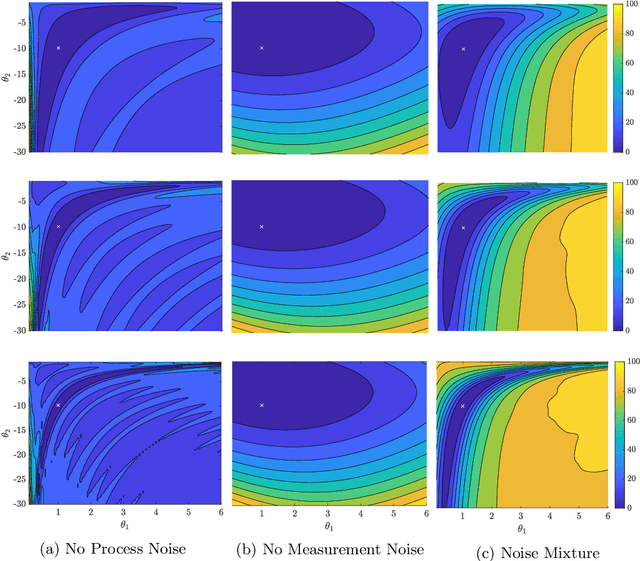
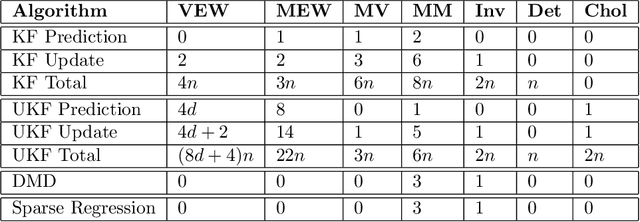
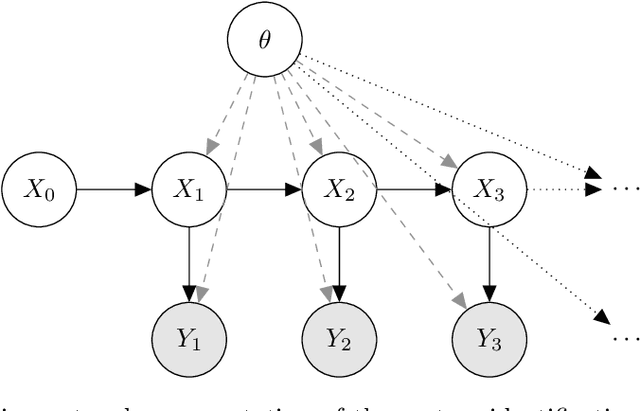

We evaluate the robustness of a probabilistic formulation of system identification (ID) to sparse, noisy, and indirect data. Specifically, we compare estimators of future system behavior derived from the Bayesian posterior of a learning problem to several commonly used least squares-based optimization objectives used in system ID. Our comparisons indicate that the log posterior has improved geometric properties compared with the objective function surfaces of traditional methods that include differentially constrained least squares and least squares reconstructions of discrete time steppers like dynamic mode decomposition (DMD). These properties allow it to be both more sensitive to new data and less affected by multiple minima --- overall yielding a more robust approach. Our theoretical results indicate that least squares and regularized least squares methods like dynamic mode decomposition and sparse identification of nonlinear dynamics (SINDy) can be derived from the probabilistic formulation by assuming noiseless measurements. We also analyze the computational complexity of a Gaussian filter-based approximate marginal Markov Chain Monte Carlo scheme that we use to obtain the Bayesian posterior for both linear and nonlinear problems. We then empirically demonstrate that obtaining the marginal posterior of the parameter dynamics and making predictions by extracting optimal estimators (e.g., mean, median, mode) yields orders of magnitude improvement over the aforementioned approaches. We attribute this performance to the fact that the Bayesian approach captures parameter, model, and measurement uncertainties, whereas the other methods typically neglect at least one type of uncertainty.